中华网家电
设为书签Ctrl+D将本页面保存为书签,全面了解最新资讯,方便快捷。
在金融风控、深度客服、代码开发等场景中,AI模型常常因“记忆”不足而做出片面判断——这不是简单的对话遗忘,而是高并发、长周期业务压力下的“业务性记忆过载”。其根源在于GPU显存(HBM)容量有限且昂贵,无法承载海量的中间推理数据(KV Cache),形成制约AI规模化应用的“显存墙”。
显存墙下的两难选择
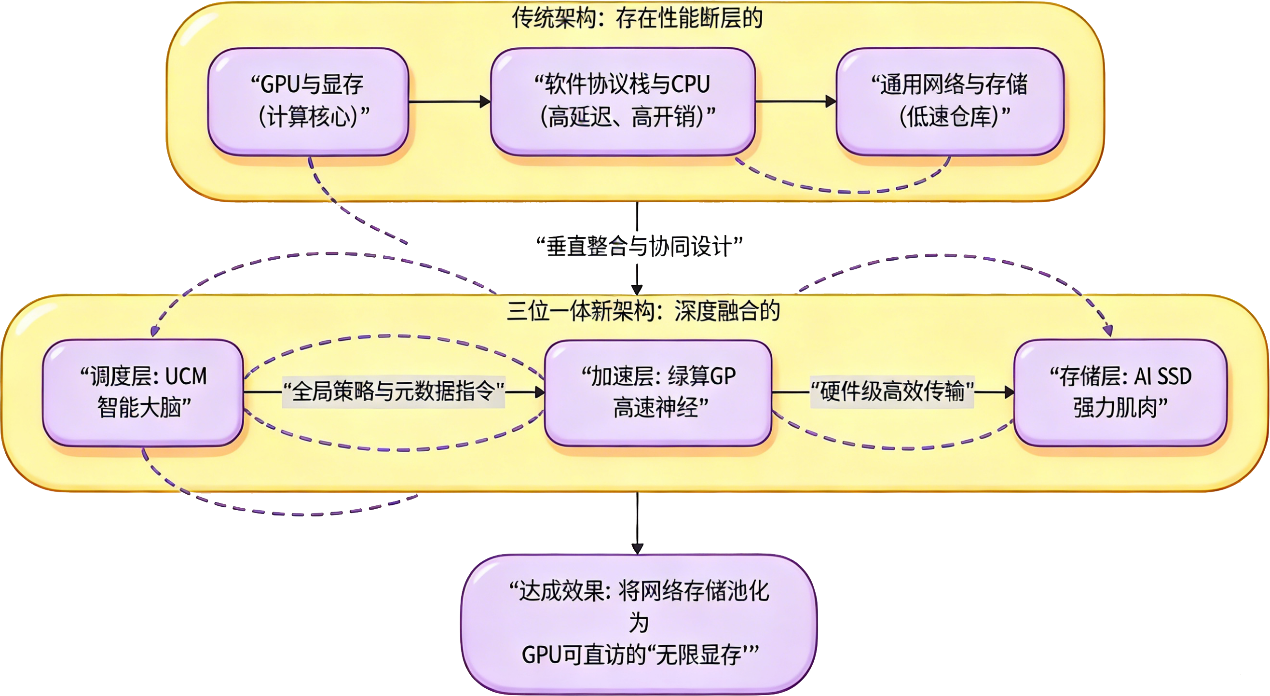
限制上下文窗口导致模型“主动失忆”,或将数据溢出至低速存储引发性能骤降。要真正突破这一瓶颈,需从系统层面重构数据供给体系。我们联合提出一种颠覆性的“三位一体”协同架构,正是围绕KV Cache的生命周期管理,实现从软件调度、数据传输到存储介质的垂直整合。
三位一体,重塑AI记忆层级
根本出路在于重新设计存储架构,将被动存储变为主动的“AI记忆外脑”。华为与绿算技术携手,提出一套从软件到硬件的垂直协同方案:
华为UCM(调度大脑)
作为全局缓存管理器,UCM实现KV Cache在GPU显存、内存与外部存储间的统一池化与智能调度。它可预测模型下一步所需数据,并实现语义级优化如Prefix Cache,显著降低重复计算,提升有效吞吐。
绿算GP(数据神经)
绿算GP全闪存储设备承担起“高速数据通道”角色,通过硬件卸载NVMe-oF协议与RDMA零拷贝传输,将网络存储访问延迟从毫秒级压缩至微秒级,让远端存储对GPU而言如同本地资源,真正实现 “网络即总线,存储即内存”。
华为AI SSD(存储肌肉)
针对KV Cache“小块、随机、高并发读取”的I/O特征进行深度优化,配备超大DRAM缓存与定制闪存管理机制,确保在高速访问下仍能提供稳定低延迟的持久化存储能力。
三者协同,将原本割裂的存储体系转化为一个可弹性扩展、性能接近内存的全局记忆池。
从“被迫遗忘”到“永久记忆”
在实际业务场景中,三者协同工作:UCM根据访问热度将KV Cache分层调度;绿算GP确保数据在GPU与AI SSD间极速流动;AI SSD则承载温冷数据并提供快速响应。这使得AI服务能长期保留历史对话上下文,在连续交互中保持记忆一致,彻底告别因显存不足导致的性能下降或中断。
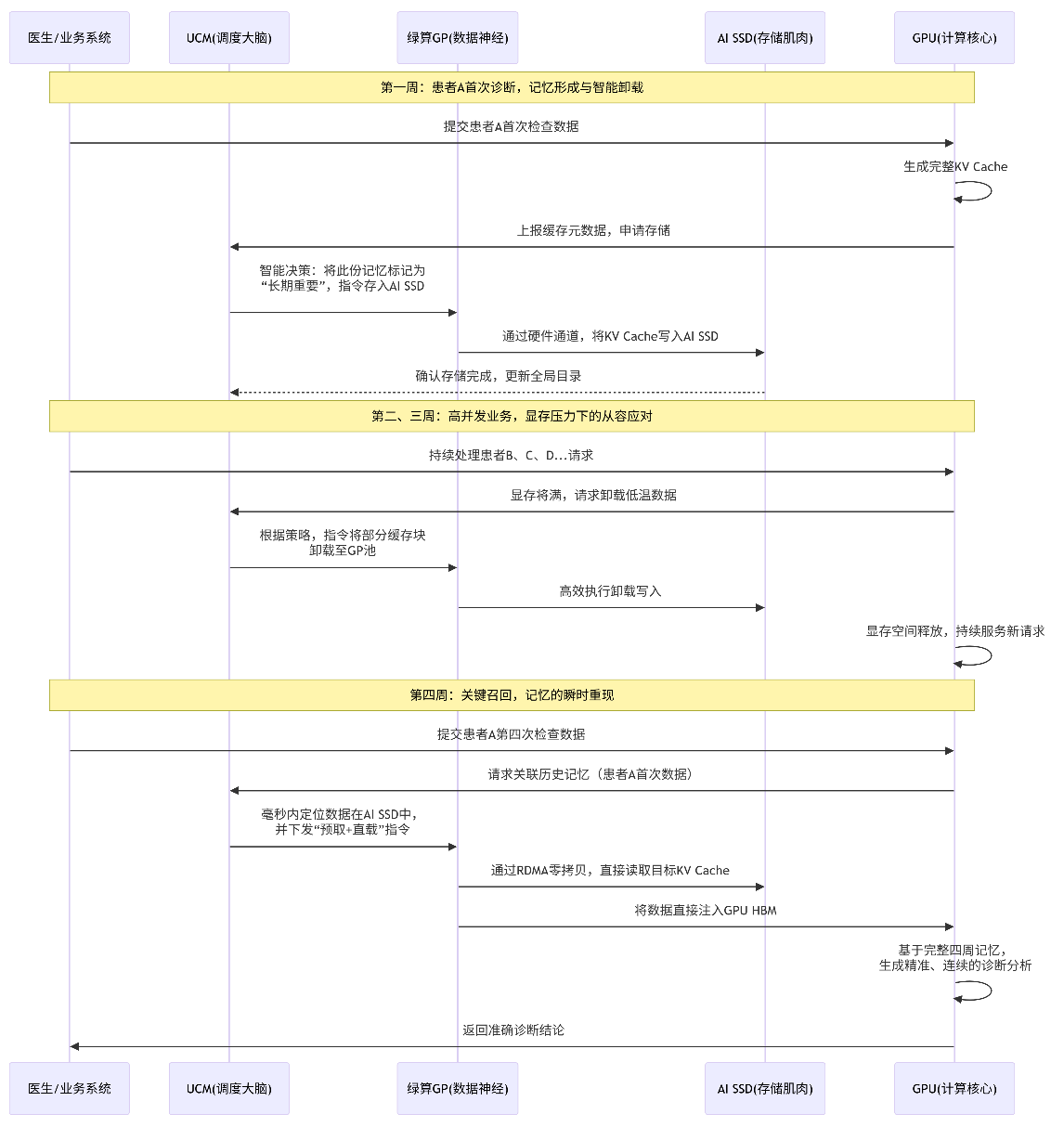
无法被传统架构复制的壁垒
该方案的核心在于深度协同设计,而非通用组件的简单叠加。绿算GP的硬件协议卸载、UCM的语义感知调度、AI SSD的负载优化,共同构成了面向KV Cache的定制化数据供给层级。这种系统级、芯片级的融合,是传统“GPU+通用存储”架构无法跨越的性能与效率鸿沟。
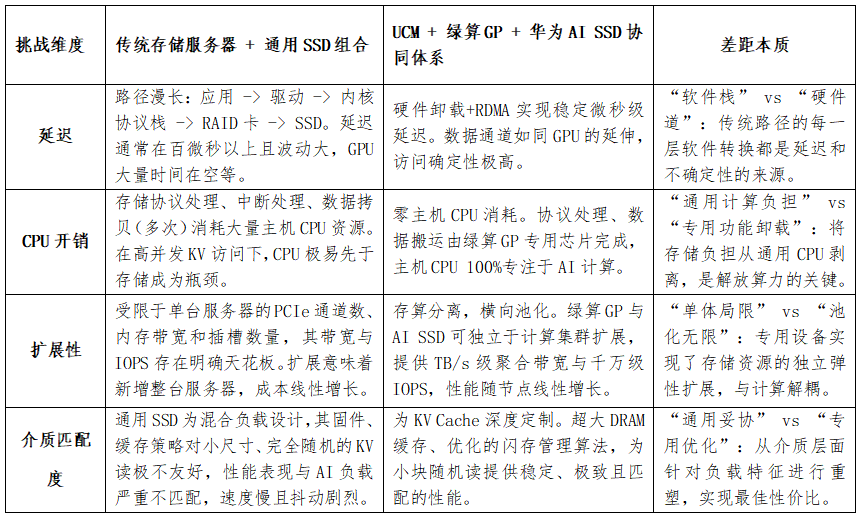
通过华为UCM的智能调度、绿算GP的极速通道与AI SSD的高性能存储,“三位一体”架构不仅打破了显存容量限制,更重新定义了AI推理的数据基础设施——使大模型具备可持续、可扩展的“永久记忆”,为AI在千行万业中的规模化、实用化落地铺平道路。
免责声明:市场有风险,选择需谨慎!此文仅供参考,不作买卖依据。
责任编辑:kj015