中华网家电
设为书签Ctrl+D将本页面保存为书签,全面了解最新资讯,方便快捷。
12月19日,智源研究院发布并解读了国内外100余个开源和商业闭源的语言、视觉语言、文生图、文生视频、语音语言大模型综合及专项评测结果。云知声山海大模型(UniGPT4.0-0730)在此次评测中表现优异。云知声山海大模型在100多个参评大语言模型中,客观评测全球第6,国内第3;主观评测全球第12,国内第8,继续稳居我国大语言模型第一梯队。这一佳绩不仅彰显了云知声在人工智能领域的深厚技术底蕴,也标志着公司在大模型技术的应用和综合能力提升方面取得了显著的进展。云知声山海大模型的卓越表现,证明了其在激烈的市场竞争中具备强劲的竞争力,并且在技术创新和应用实践上不断取得突破。
01.能力卓越,山海大模型多项评测名列前茅
智源研究院的大模型评测平台FlagEval自2023年6月上线以来,已覆盖全球800余个开闭源模型,超过200万条评测题目,成为全球大模型评测的重要平台。此次评测,FlagEval在评测方法与工具上联合了全国10余家高校和机构合作共建,不仅扩展、丰富和细化了评测任务,还新增了数据处理、高级编程和工具调用的相关能力与任务,以及面向真实金融量化交易场景的应用能力评估。
在FlagEval“大语言模型评测能力榜单”中,山海大模型(UniGPT4.0-0730)在主客观两大评测维度中均展现出了非凡的实力。本轮评测主要聚焦对话模型,其中主观评测更侧重于考察中文能力。在涉及约2.2万道题目、覆盖40余个语言模型的广泛评测中,山海大模型凭借其卓越的性能,赢得了业界的广泛认可。
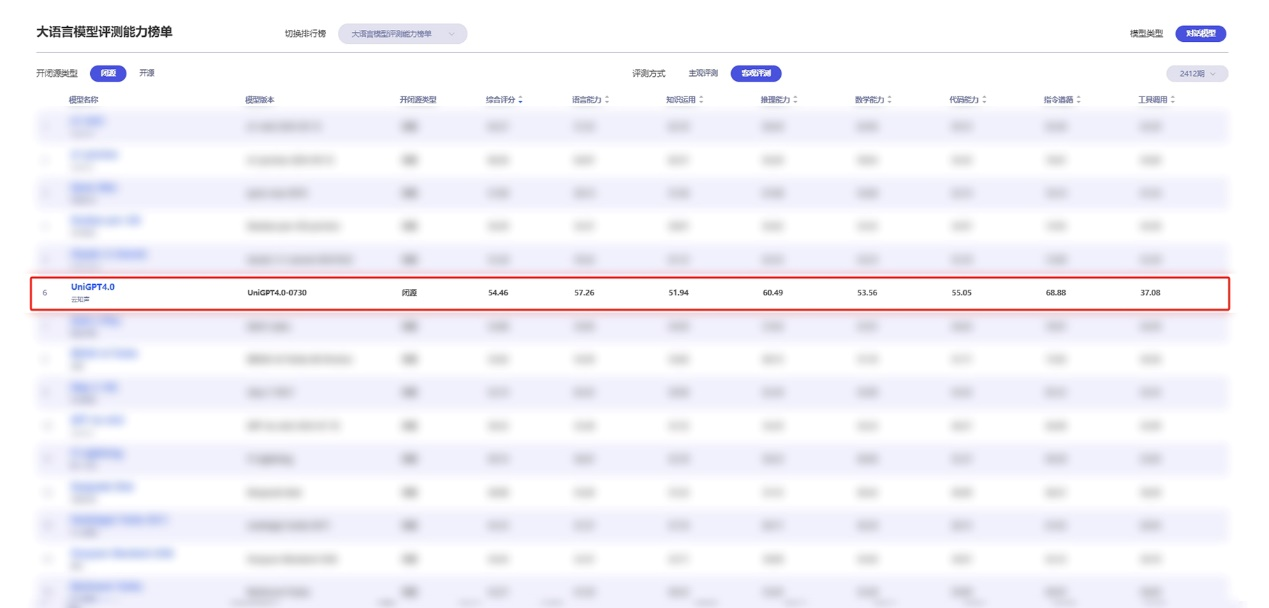
在客观评测方面,该榜单详尽涵盖了语言能力、知识运用、推理能力、数学能力、代码能力、指令遵循、工具调用七大评估类别,全方位考察各项技能。山海大模型(UniGPT4.0-0730)以54.46的综合评分,在榜单中位列第3,这充分彰显了其坚实的综合基础。特别是在代码能力方面,山海大模型得分高达55.05,荣获国内第1,进一步凸显了其在编程和代码处理方面的卓越才能。同时,其数学能力得分53.56,也使其荣获国内第2,再次证明了其在解决复杂数学问题上的非凡实力。
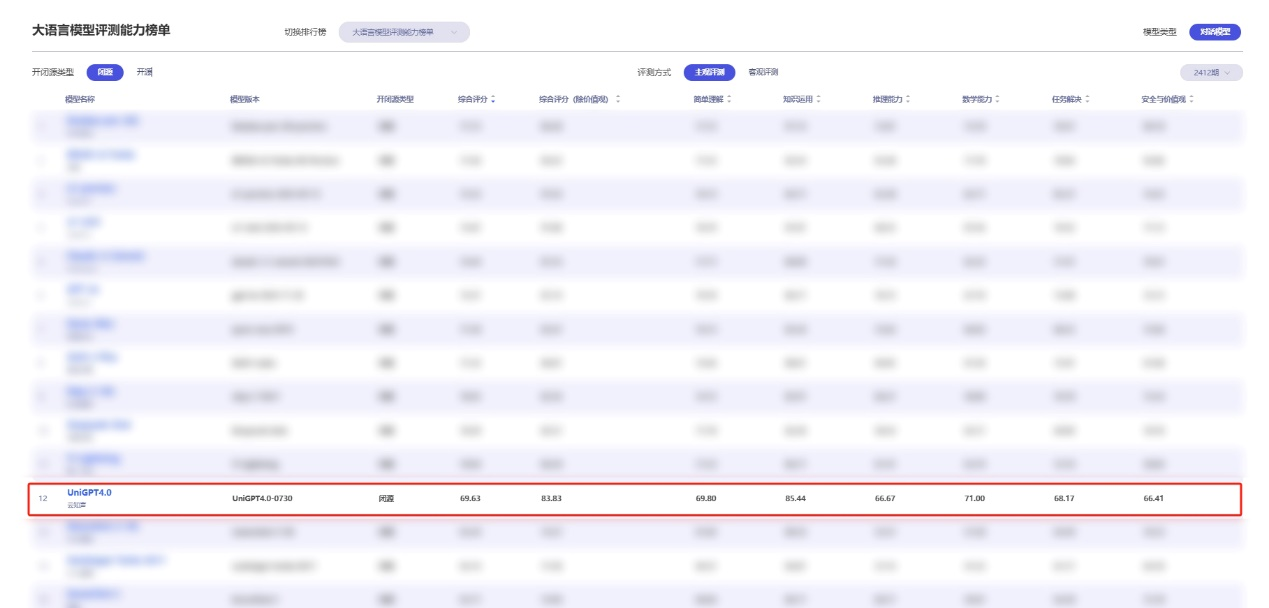
在主观评测方面,该榜单精心设置了简单理解、知识运用、推理能力、数学能力、任务解决、安全与价值观六大评估维度,全面衡量各项能力。山海大模型(UniGPT4.0-0730)凭借69.63的综合评分,在榜单中脱颖而出,位列第8名,充分展示了其强大的综合性能。此外,其数学能力得分高达71,位居国内第3名,进一步凸显了山海大模型在解决复杂数学问题上的出色能力。
02. 智慧赋能,加速AI应用落地与产业升级
随着人工智能技术的快速发展,大模型已成为全球科技竞争的新高地、未来产业的新赛道、经济发展的新引擎。当前,通用大模型、行业大模型以及端侧大模型正如雨后春笋般层出不穷,大模型产业的应用落地步伐显著加快。
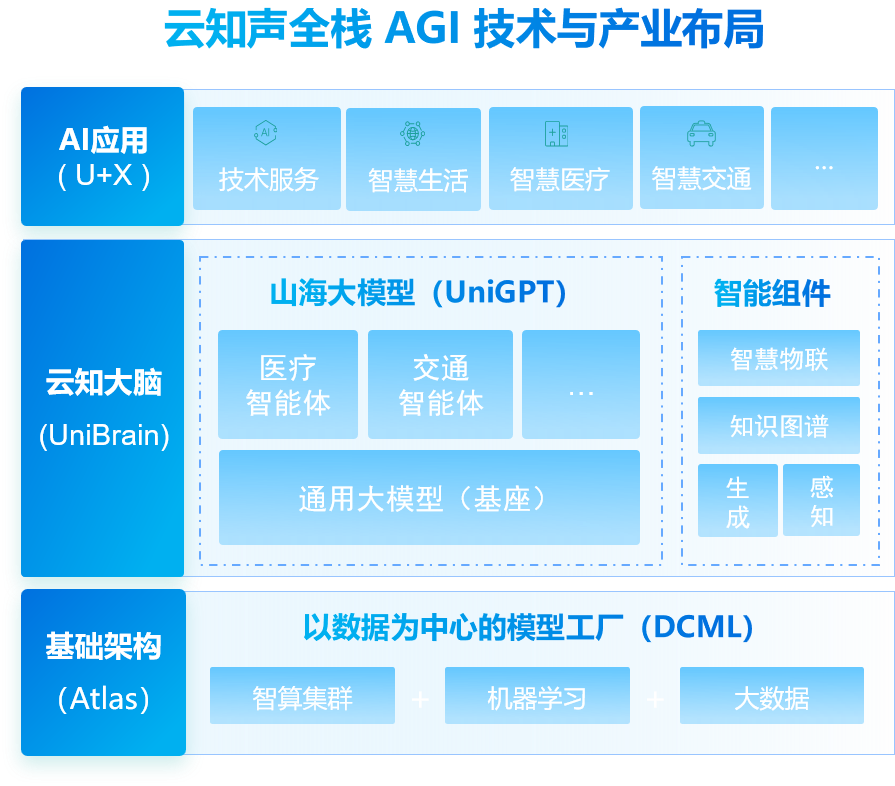
作为国内顶尖的人工智能独角兽企业,云知声于2016年开始建立Atlas人工智能基础设施,并以此为基础,构建云知大脑(UniBrain)技术中台——以山海(UniGPT)通用认知大模型为核心,结合多模态感知与生成、知识图谱、物联平台等智能组件,为云知声智慧物联、智慧医疗、智慧座舱、智慧交通等业务提供高效的产品化支撑,持续推动千行百业的智慧化升级。
山海大模型作为云知大脑的核心,在实际应用中展现出了卓越的潜力与实力。通过持续的技术创新和丰富的应用场景实践,山海大模型不仅在通用能力上达到了世界一流水平,而且在专业能力上也表现出色,处于行业领先地位。
目前,山海大模型已相继在OpenCompass大模型评测、SuperCLUE中文大模型基准测评、MedBench评测、Flageval大模型评测、SuperBench、MMMU等多个权威评测中屡创佳绩,稳居国内大模型第一梯队,展现了其强大的通用能力。在专业能力层面,其基于山海大模型孵化的医疗大模型在CCKS 2023 PromptCBLUE医疗大模型评测中夺得通用赛道一等奖,并在2024年5月和6月的MedBench评测中连续登顶榜首。此外,在2024年全国智慧医保大赛中,凭借“基于大模型的DRG结算清单智能生成方案”,团队在总决赛中荣获一等奖。
此次荣登智源FlagEval“百模”评测榜前列,不仅是对山海大模型技术实力的有力证明,更是对其在人工智能领域持续创新和深耕细作的肯定。未来,云知声将继续秉承创新理念,不断突破技术瓶颈,为人工智能产业的发展贡献更多力量,推动AI技术创新与行业应用的深度融合。
责任编辑:kj005
文章投诉热线:157 3889 8464 投诉邮箱:7983347 16@qq.com