中华网家电
设为书签Ctrl+D将本页面保存为书签,全面了解最新资讯,方便快捷。
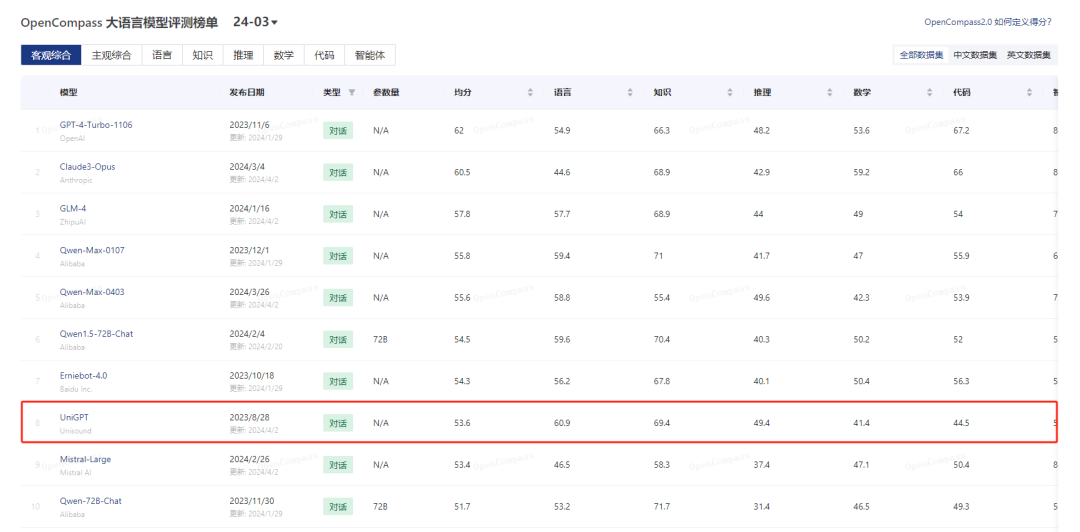
近日,山海大模型完成新一轮迭代升级,并在最新的OpenCompass大模型评测中取得综合性中英文双语客观评测得分53.6、综合性中文主观评测得分42.2的优异成绩,在参与测评的全球大模型厂商中排名第六。评测结果显示,其在中英文双语客观评测中的语言、知识、推理能力,在综合性中文主观评测中的创作能力已超越GPT-4。
综合性中英文双语客观评测排名

综合性中文主观评测排名
作为上海人工智能实验室开源的大模型评测体系,OpenCompass致力于探索最先进的语言与视觉模型,为工业界和研究社区提供全面、客观、中立的评测参考,从而根据不同能力维度的评测分数指导大模型的优化与进步。
OpenCompass 月度榜单从基础能力和综合能力的设计出发,构造了一套高质量的中英文双语评测基准,涵盖语言与理解、常识与逻辑推理、数学计算与应用、多编程语言代码能力、智能体、创作与对话六个方面二十余项细分任务,力图对近期的主流开源模型和商业 API 模型进行全面评测分析。
此次榜单囊括了国内外 40 个大语言模型,评测数据集采用中英文闭源数据集,包括综合性中文主观评测和综合性中英文双语客观评测。云知声山海大模型综合性中英文双语客观评测得分53.6,综合性中文主观评测得分42.2,排名国产大模型厂商第四、全球大模型厂商第六。从各项数据看,其在语言、知识、推理、创作等方面表现优异,显现出强劲的综合实力。
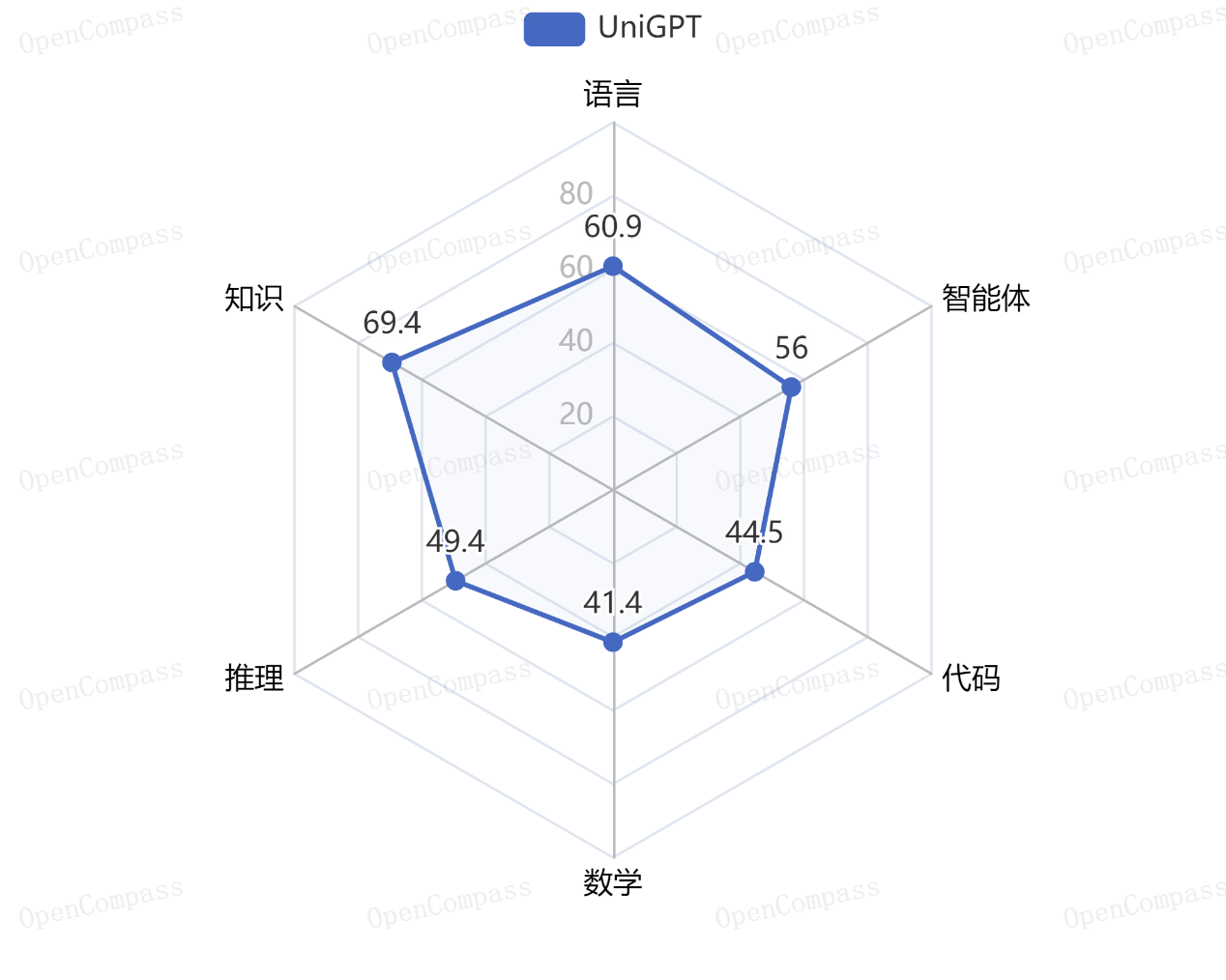
综合性中英文双语客观评测得分
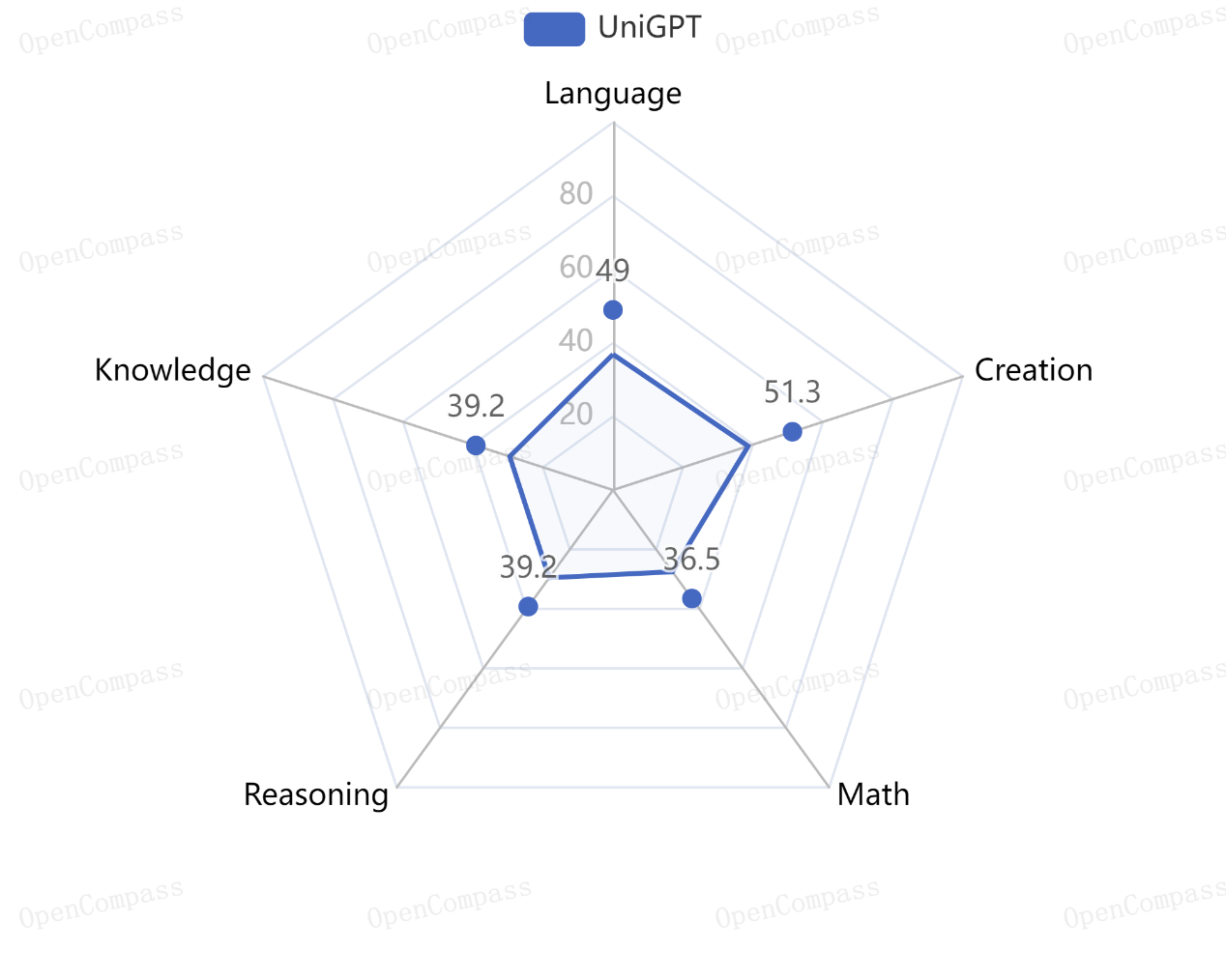
综合性中文主观评测得分
而山海大模型之所以能够在众多大模型中脱颖而出,得益于其在技术上的一系列创新和优化——在本次大模型升级中,云知声引入了自我演进偏好学习技术,使得大模型能够通过自我对弈微调(SPIN)实现自我提升。在高质量数据生成方面,云知声结合RLHF和RLAIF方法,生成大量偏好数据,并采用k-Center Greedy算法确保数据的多样性和覆盖度。此外,云知声还建立了一个全面的自动化评测体系,以此实现对模型效果的快速评测,进而支持大模型的迭代和优化。
自2023年5月发布以来,山海大模型始终保持高速迭代,其在C-Eval全球大模型综合性评测、CCKS 2023医疗大模型评测等权威赛事上屡获佳绩,展现出全面的通用能力和卓越的专业能力,成功跻身大模型第一梯队。此次评测,是山海大模型出色实力的又一次印证,也将鞭策其继续加速迭代,持续引领大模型研发与落地。
作为中国AGI技术产业化的先行者,云知声于2016年开始打造Atlas人工智能基础设施,并以此为基础,构建云知大脑(UniBrain)技术中台——以山海(UniGPT)通用认知大模型为核心,结合多模态感知与生成、知识图谱、物联平台等智能组件,为云知声智慧物联、智慧医疗、智慧交通等业务提供高效的产品化支撑,持续推动“U(云知大脑)+X(应用场景)”战略布局。

云知声全栈AGI技术与产业化布局
山海大模型作为云知大脑的核心,其能力体系涵盖语言生成、语言理解、知识问答、 逻辑推理、代码能力、数学能力等。此外,为提高大模型在具体场景的应用落地水平,山海大模型在通用能力基础上,增强物联、医疗、交通等行业能力,致力为客户提供更智能、更灵活的解决方案,加速千行百业的智慧化升级。
目前,云知声正依托山海大模型技术能力的加速迭代,逐步深入到智慧医疗、智慧座舱、智慧轨交、智慧政务等具体场景,不断释放AGI的更多可能。
在智慧医疗领域,云知声基于山海大模型打造的门诊病历生成系统已落地北京友谊医院,有效提升了病历撰写效率与质量;在智慧政务领域,云知声率先开发出深圳首个政务大模型“龙知政”,全场景赋能提升政府治理水平;在智慧座舱领域,云知声通过山海大模型赋能吉利睿蓝汽车打造情感型虚拟助手,为用户带来全车全场景的情感化智能交互体验;在智慧轨交场景,云知声山海大模型“入驻”南宁火车东站,打造更具人性化的智能客服,助力实现换乘节点无缝高效换乘,为乘客带来更快捷、更便利的出行体验,相关案例也于近期被央视《焦点访谈》栏目报道。
随着大模型技术的不断进步和创新,我们有理由相信,世界将变得更加智能和互联。我们期待,山海大模型能够实现更多新的突破,开辟更广更深的技术边界,拓展更多尚未触及的应用场景。
责任编辑:kj005
文章投诉热线:182 3641 3660 投诉邮箱:7983347 16@qq.com










