中华网家电
设为书签Ctrl+D将本页面保存为书签,全面了解最新资讯,方便快捷。
大模型的火爆已经呈现“燎原”之势,从集群到单点,从聚合到分布式,从云端到边端,这些发展势头都充分的印证了大模型“普惠”的趋势。可是在智能安防、智慧园区、机器视觉等真实场景中,因物理资源和能耗的限制,大模型的“边侧化”并不顺利——算力低、功耗低、内存低,带宽差,这种“三低一差”导致模型一量化就掉点,场景稍有变化就得重新设计,这些问题好像除了“大刀大枪”的改模型外就没有其他办法。
如果能让硬件自己“动”起来,自己适配模型的变化,那么上述问题就会迎刃而解,这听起来有点匪夷所思,但确实是最为高效的解决办法。而事实上,在计算机架构专业就有这样的研究:可重构计算。
基于可重构计算的芯片不是“更快的芯片”,而是“会变形的芯片”
传统专用芯片(ASIC)在处理大模型边侧部署时,最核心的矛盾不是算力不够,而是太僵化。当场景稍微一变,或者模型换了参数,又或者量化方式变了等, ASIC就会“无所适从”,处理办法只能是大量软件补丁或者干脆“砍模型”。这种“削足适履”的方法基本上就是算法追着硬件跑的模式——用大模型的“缺胳膊少腿”和“瞎一只眼”来换取部署,暂且不说这种方式周期长、专业强、“易猝死”,只说部署后的效果,也是“一言难尽”:大模型已经改成“如花”,物是人非虽能忍,但是糟糕的精度和清澈如大学生般的输出结果怎么忍?
总之,一句话:让硬件的“活”去适配大模型的“活”才是解决这类问题的核心方法论。说起可重构,虽然不是什么新词,但是研究门槛却极为高,——这是一种基于专用和灵活之间的架构,既有像GPU那般的通用灵活性,又有像ASIC那般的专用性。乍一看,可重构计算好像是要求向左看的同时又要向右看,对!这才是这项技术最难的地方。很多国内外的研究就是“卡死”在了这一环,有些只能从数据方面入手,就如好像给FPGA加上了“数据配置器”一样,这种实现虽然也是可重构,可距离真正的硬件“活”起来,还有一定的差距。
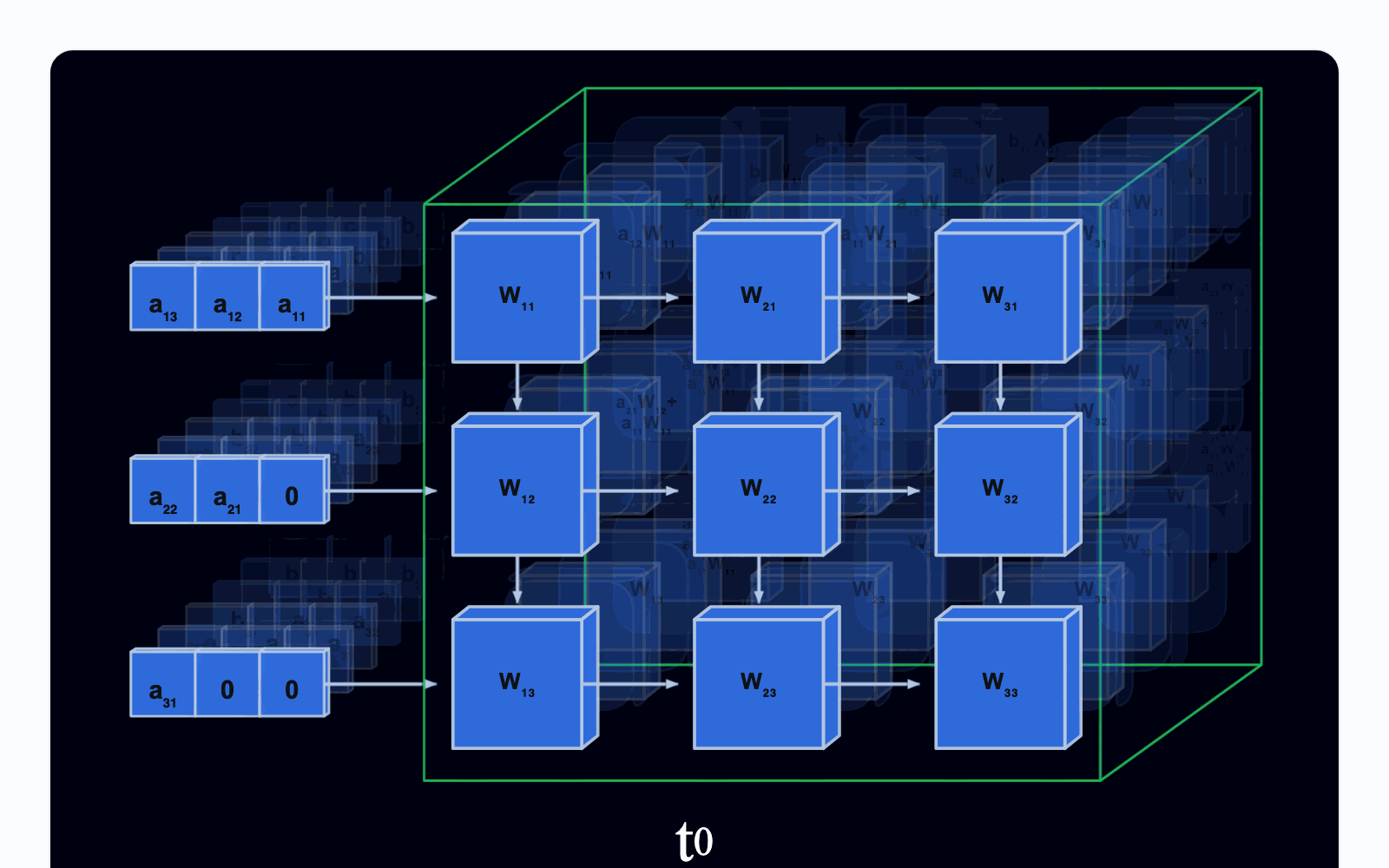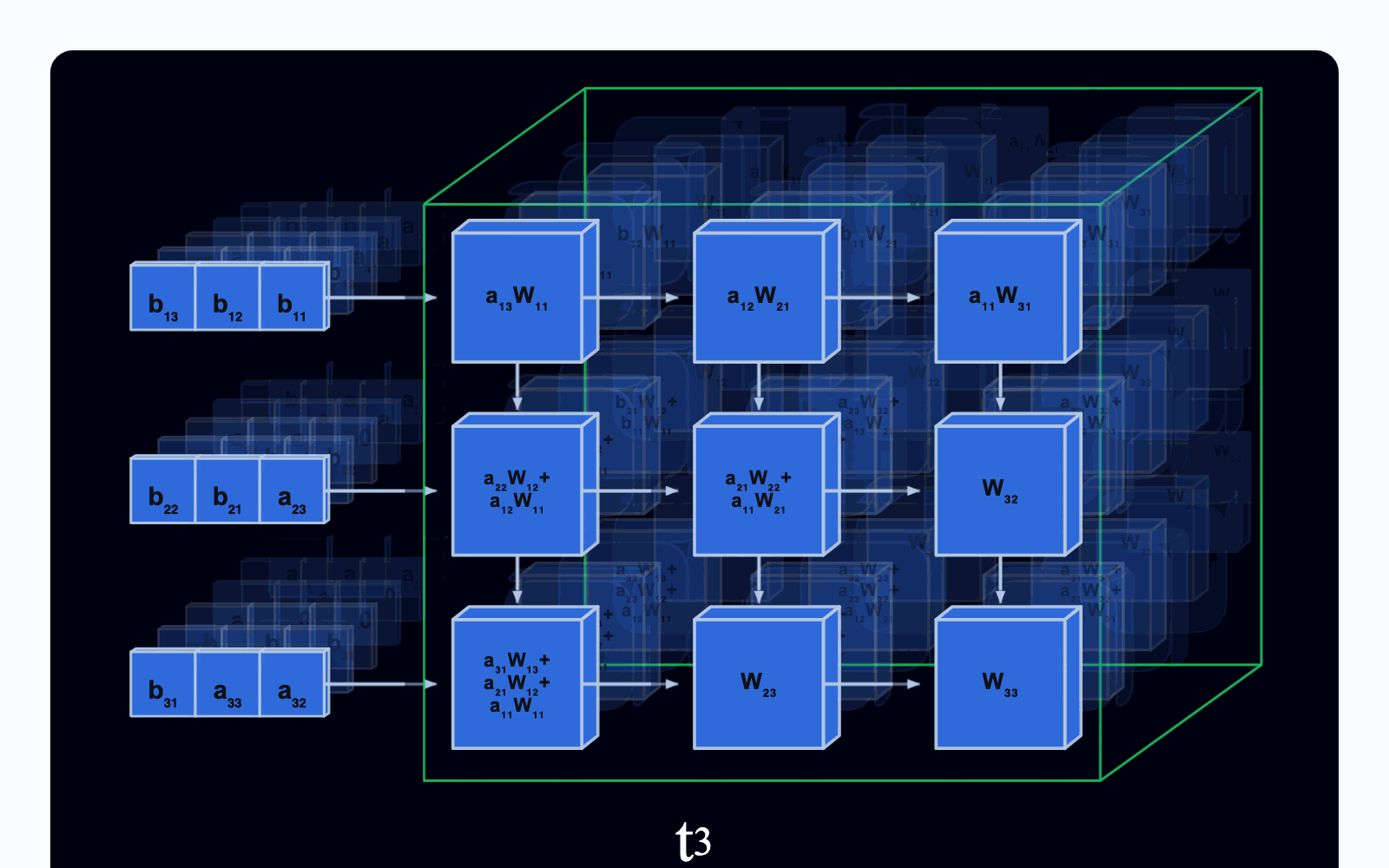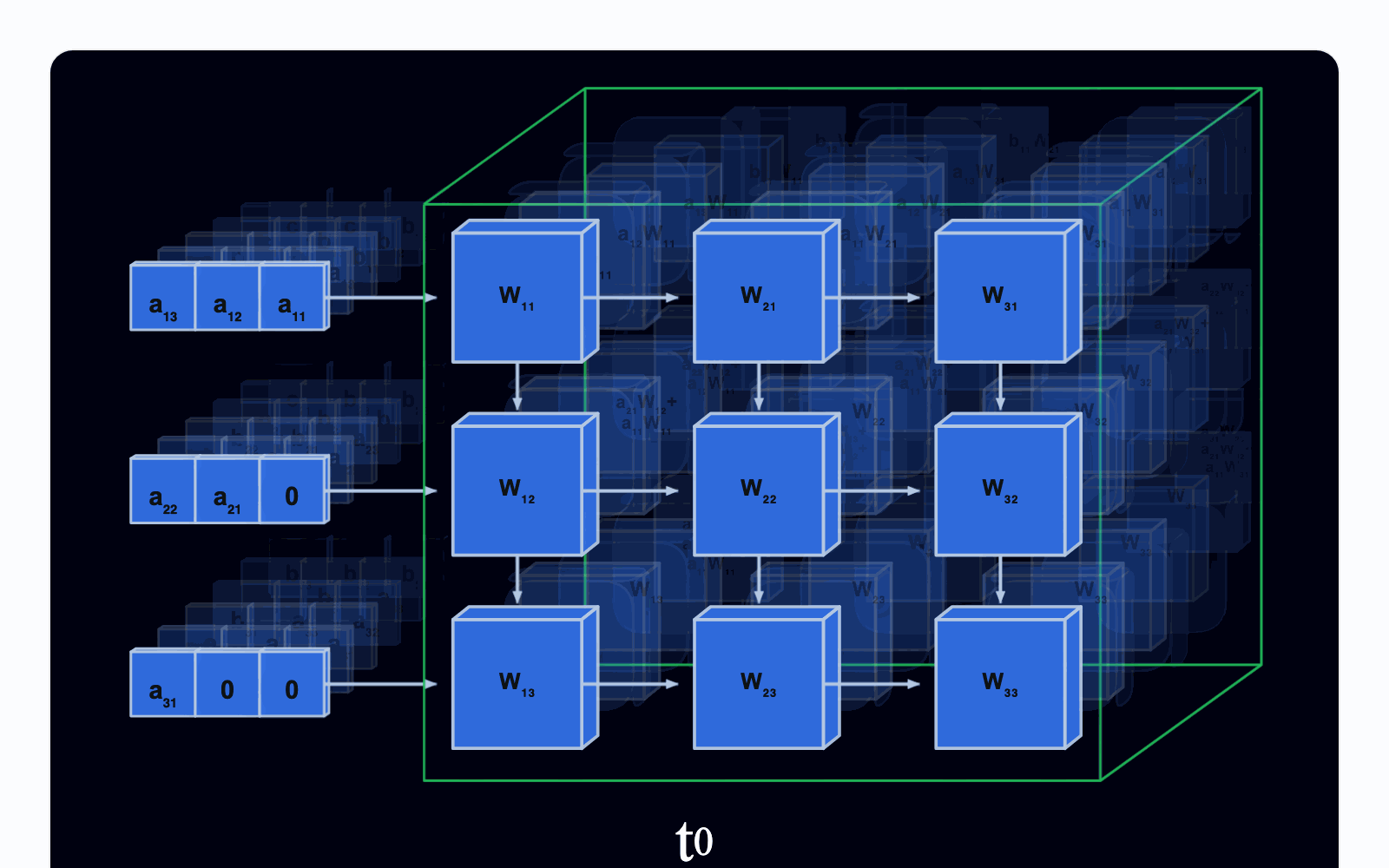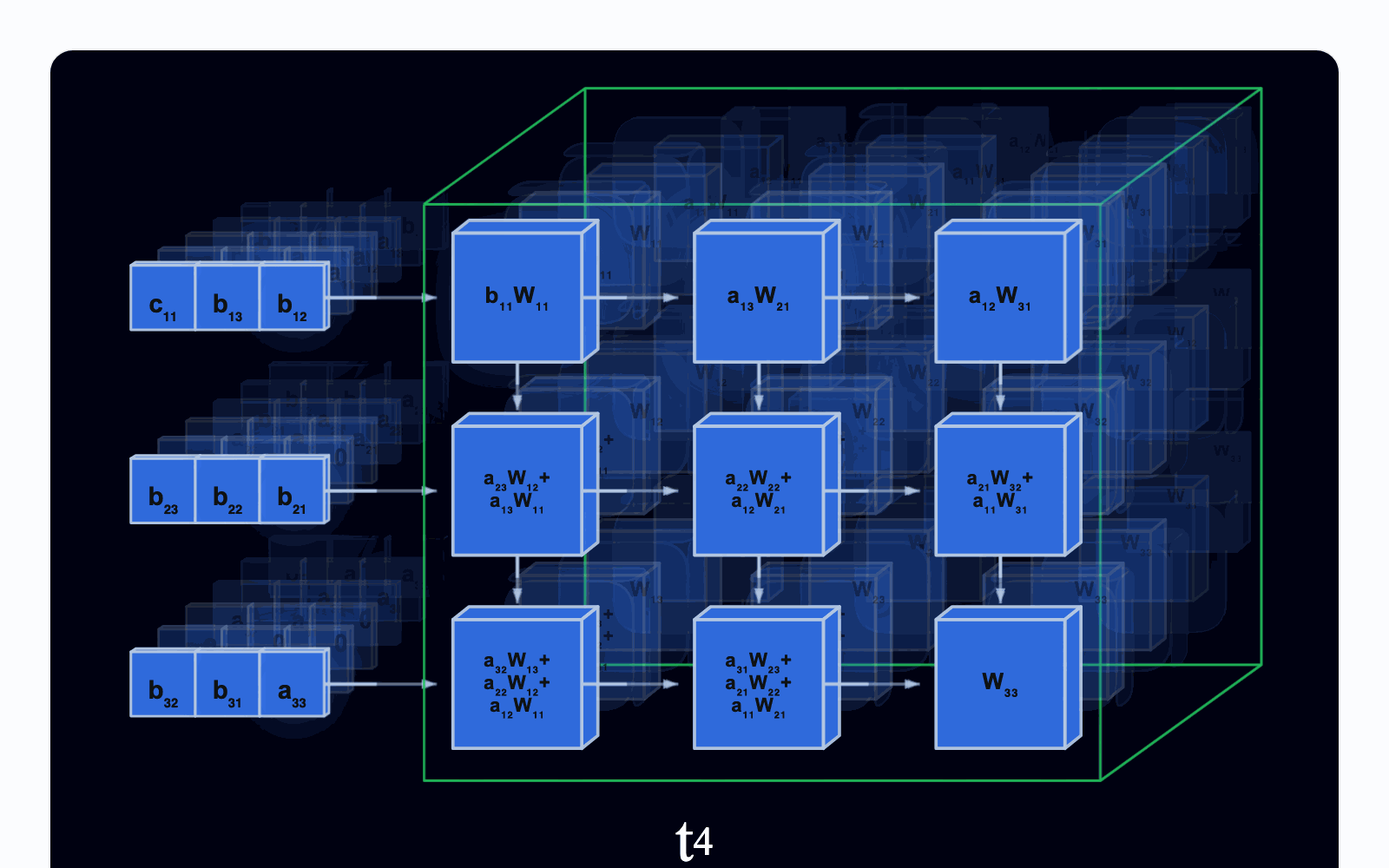
据“信息技术与标准化”报道,国内有研究机构最近在可重构方向上有了重大突破,广州万协通人工智能实验室实现了基于动态配置的可重构计算架构TPU芯片, 并在该芯片上实现了大模型4bit量化,量化后的大模型各项性能不仅并未降低,而且在效率和内存占有率方面有较大提升,这一突破标志着大模型落地应用的重大创新,也意味着我国可重构技术走在了世界前列。万协通的动态配置可重构技术的底层基础是可重构计算单元(BOU),这里可以把它理解为一个具备独立运算能力的最小“原子单元”,通过可编程运算配置总线和调度总线连接成张量阵列,当面对不同的模型算子或运算任务时,调度器会像指挥一支“工程队”一样,按需组合这些BOU单元,如处理简单的矩阵乘法,只需调动2~4个BOU形成轻量计算块;而应对Transformer多头注意力这样的高维运算时,则可以协调数十甚至上百个BOU构成计算阵列协同完成。这种计算范式可不是简单意义上的“灵活”,而是基于可配置运算的硬件算子级别的动态重组。引用万协通人工智能实验室的介绍:它实现了“单一硬件架构对4bit量化全场景运算需求的全覆盖”。
3%的损失换全参数量化
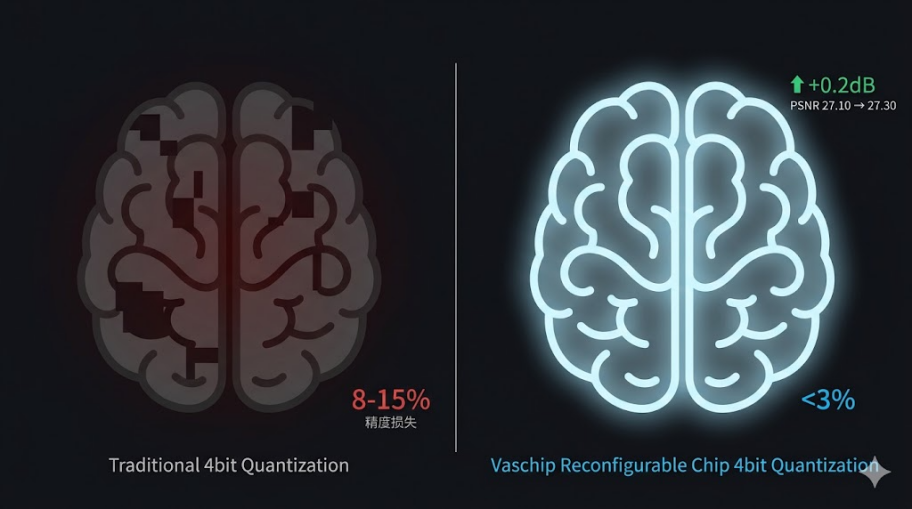
纵观大模型在众多边侧落地的案例,不管是DeepSeek系列还是Qwen系列,绕不开的一个话题就是:4bit量化,这也是目前行业内公认的大模型能落地的最有希望的技术方向,但痛点也很现实:精度掉得厉害。传统PTQ策略在4bit量化下,精度损失通常在8%~15%,而且很多关键层不得不保留16bit或32bit,压缩效果大打折扣。
万协通人工智能实验室的实测数据则让人眼前一亮:在Qwen2.5-7B-Instruct的4bit PTQ量化任务中,不仅实现了全参数的量化,而且尤其让人欣慰的是整个模型精度损失被控制在3%以内,要知道这个损失率,除了AI评估卡或AI基准卡,即使放到其他AI集群服务器上,也不一定能达到。从这一点来看,万协通的动态配置可重构TPU芯片确实对大模型量化部署有很好的适配性。
另一个较为新颖的表现是在视频超分任务——在Vid4数据集上,4bit模型的PSNR达到27.30dB,甚至略高于全精度模型的27.10dB。结构相似性也从0.7800小幅提升到0.7820。这意味着,在真实画面中,文字、纹理细节清晰可辨,没有明显边缘模糊。
这可不是理论上的“接近”,而是工程上极限的逼近。
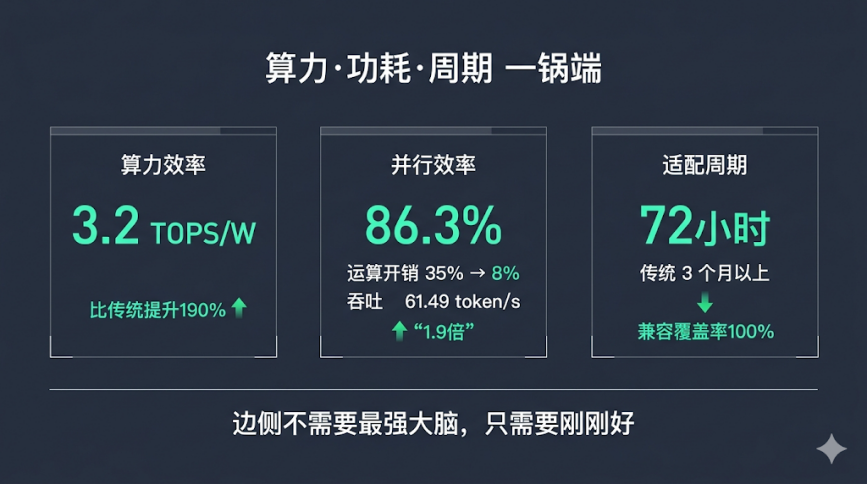
算力、功耗、适配周期“一锅端”
边侧设备最怕的就是“按下葫芦浮起瓢”——算力上去了,功耗爆了;模型跑起来了,硬件又“猝死”了;好不容易算力可以了,功耗将将够了,可周期又到3年后了……万协通人工智能实验室提出的可重构能否在这三个维度上有所建树呢?上数据:
1) 算力效率:单位能耗算力密度达到3.2 TOPS/W,比传统固定架构TPU提升190%以上。在边侧设备典型5~15W功耗约束下,可稳定支撑4bit量化模型全流程运算。
2) 并行效率:通过流水线式数据并行架构,张量运算并行效率提升到86.3%,辅助运算开销从35%降至8%以下。多任务并行场景下,输入吞吐性能达到61.49 token/s,较传统专用芯片提升1.9倍。
3) 适配周期:对不同边侧场景的4bit量化算法兼容覆盖率达到100%,适配周期缩短到72小时以内。相比之下,传统专用芯片通常需要3个月以上。
这些数字背后是一个很现实的判断:边侧不需要“最强大脑”,需要的是“刚刚好且能快速部署”的硬件。
解难题远比秀操作来的实在,回答一个让人质疑的问题:为什么万协通可以?是在秀操作还是在真正解决问题?
答案:看数据,看过程,看结果!
数据上面已经有了,让我们再从技术产生的过程上溯源一下:万协通动态可重构的基石是BOU,也就是说,任何运算对于BOU来说都是可以通过一定的配置实现的,审视AI大模型可以知道,无论是神经网络、卷积积分还是self-attention等,这类运算可以归纳为张量运算、张量微分运算和激活运算,从线性理论出发,也就是齐次线性或齐次非线性(主要是针对激活函数)运算,再进一步,从群论观点看就是在域中基于某种运算的多项式逼近,如果想完成基础运算硬件算子的研发,就需要在这个方向持之以恒的研发和突破。而回顾万协通的发展过程,正是一家以基础运算算子研发为核心技术的芯片公司,他们不仅实现了可重构TPU芯片,而且还实现了AI超算芯片和AI安全芯片,从这个角度审视,可能也就能解释上述质疑了。
看结果,基于可重构TPU技术的视频大模型边缘计算的相关资料显示,这一芯片解决方案已经在智能安防、智慧停车、智慧园区等真实场景中完成验证并取得了很不错的效果。
更重要的是,动态配置可重构架构并非只为某一款大模型定制,而是面向开源生态开放适配。万协通正在推进针对工业、金融、政务、民生服务等不同数字化转型场景的分领域适配工作。
结论:动态配置可重构TPU这条路,不是最炫的技术路线,但很可能是离产业最近的一条。它没有试图用一套架构解决所有问题,而是选择了一种更务实的方式——让硬件学会适应算法,而不是反过来。
责任编辑:kj015









