中华网家电
设为书签Ctrl+D将本页面保存为书签,全面了解最新资讯,方便快捷。
汽车产业正迎来智能化新时代。如果电动化是“上半场”,那么智能化便是“下半场”。AI已成为行业竞争的新战略支点,推动智能座舱和自动驾驶技术的快速发展。智能座舱和自动驾驶殊途同归,以多模态大模型为中心的汽车智能化能力成为当前汽车产业发展的焦点。
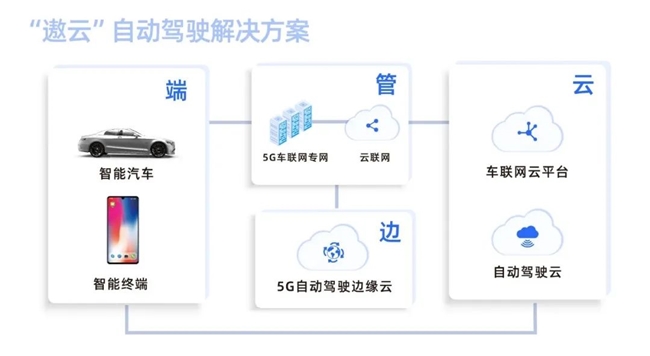
万马科技(股票代码:300698)全资子公司——优咔科技,打造“遨云”智算解决方案,为汽车智能化提供一站式的算力及工具链支持,助力汽车行业采集、处理纷繁复杂的数据并进行高效的算法训练。在自动驾驶领域,多模态大模型VLM/ VLA已经得到初步应用,但行业仍面临端侧算力不足、云侧算力建设周期长成本高等问题。当算力军备竞赛陷入边际效益陷阱时,DeepSeek用新架构、新思路为AI的发展打开了新的可能性空间。
DeepSeek多种尺寸的开源大模型、算法架构以及优化的训练方法,会从多个关键角度为自动驾驶带来了前所未有的变革,成为推动中国汽车产业智能化前行的核心力量。
“遨云”智算解决方案完成DeepSeek全面集成
DeepSeek全面集成,支持一键部署
在优咔“遨云”大模型应用平台中,已全面开展包括R1在内的DeepSeek全系列模型适配工作,以满足不同规模参数量模型的个性化部署需求。目前可一键本地部署体验DeepSeek,近期将开放微调功能。
常州智算中心提供高效AI计算服务
优咔常州智算中心已经部署满足合规要求的车企专用自动驾驶及大模型开发工具链,深度整合英伟达NVAIE产品,提供高效的大模型部署环境。经过近期的部署及测试,DeepSeek在优咔常州智算中心的服务器上运行的表现优异。优咔常州智算中心已向客户开放该功能,某头部车企客户正在进行试用。
同时优咔科技正在与战略合作伙伴一起,针对优咔常州智算中心的算力及网络架构,对DeepSeek-R1模型进行针对性的优化工作。
DeepSeek在自动驾驶中的应用思考
MOE和PTX技术大幅降低训练微调成本加速技术落地
在智能驾驶模型的开发过程中,微调成本曾是阻碍技术快速迭代和广泛应用的一大难题。传统的多模态大模型微调需要大量的计算资源和海量的标注数据,耗费大量的人力、物力和时间。DeepSeek大模型凭借其独特的架构和先进的算法,改写了这一局面。DeepSeek在仅2000个GPU的算力支持下,以不足600万美元的投资和两个月的时间完成训练任务。相比之下,其他大模型往往需要16000个GPU和更高的成本。这种显著的效率提升为自动驾驶技术的升级迭代提供了强有力的技术支撑。MOE和PTX等架构及编程技术的应用,将显著改善多模态大模型训练成本高昂的问题。
知识蒸馏重构自动驾驶成本提高自动驾驶普适性
目前城市NOA系统成本仍高于8000元(单车),制约20万以下主力市场渗透。DeepSeek通过算法优化和模型压缩、蒸馏等技术,大幅降低了单位算力需求。运用DeepSeek及其优化技术有望将城市NOA硬件成本压至3000元级,触发10-15万车型标配潮,决策模型推理能耗降低80%,高阶智驾对车端芯片的算力要求进一步降低,也将更有利于“舱驾一体”、“行泊一体”等架构的推进。由于DeepSeek以NLP任务为主,其知识迁移至自动驾驶CV任务需解决模态差异(语言→视觉),需引入跨模态蒸馏技术(如通过CLIP-like对齐视觉-语言特征);同时车端模型需满足毫秒级延迟要求(如10ms内完成一帧处理),蒸馏后的小模型需在算力(TOPS)和内存(MB级)上与车载芯片匹配。
强化学习革新训练过程提升驾驶安全性
尽管强化学习在自动驾驶的规划和控制阶段得到了广泛的应用,但自动驾驶的感知识别能力,例如对道路环境、障碍物、行人等的识别与判断,当前主流的方式是采集海量的人类驾驶行为,进行模仿学习。训练过程需要采集海量数据,并通过大规模集群进行训练的,遵循Scaling Law法则,成本较高。而DeepSeek在训练过程中采用了强化学习的方法,为自动驾驶未来的训练数据集筛选与裁剪提供了可行的思路。
深化端到端复杂场景理解简化系统架构
由于车端算力有限,现在智驾端到端大模型普遍面临一个推理速度的问题。所以我们看到有些车企用“双智”系统来解决这个问题:“快“系统解决大部分场景,”慢“系统解决长尾的复杂场景。也有一些车企认为,”双智“系统只是一个过渡方案,随着技术的迭代,最终会走向一个系统。而DeepSeek的高效推理技术架构,有望加速这个进程,实现真正的单模型端到端智驾。
结语
DeepSeek的创新技术正在重塑智能驾驶格局。优咔科技将持续采纳DeepSeek的先进经验与最佳实践,依托“遨云”智算方案,加速智能驾驶与智能座舱技术落地,助力车企构建数据闭环,实现行业领先。
责任编辑:kj005
文章投诉热线:157 3889 8464 投诉邮箱:7983347 16@qq.com











