中华网家电
设为书签Ctrl+D将本页面保存为书签,全面了解最新资讯,方便快捷。
StarRocks TSC Member,镜舟科技 CTO 张友东以“Lakehouse Is All You Need”为题做了开场演讲,深入解读 Lakehouse 的演进趋势以及 StarRocks 在 Lakehouse 方向的技术深耕与创新。
社区发展概览
StarRocks 自 2021 年 9 月开源以来,社区持续保持高速发展。GitHub Star 数已超过 9300,超过 400 名开发者参与社区贡献,对齐到三年时间里,StarRocks 是同类开源项目里增长最快的。

随着数据分析对企业经营的重要性日益增加,StarRocks 的应用已经在多个行业落地。在互联网领域,包括腾讯、阿里巴巴、小红书、携程、贝壳、滴滴在内的多家知名企业已将 StarRocks 投入生产环境。排名前 50 的互联网公司中,超过一半正在使用 StarRocks。互联网企业的数据技术选择是业界的风向标,这些头部企业的采用进一步证明了 StarRocks 代表着先进的生产力。
在新经济和新制造行业,StarRocks 也发挥了显著作用。例如,领先的零售企业(华润万家、大润发)、物流企业(京东物流、顺丰)、手机制造厂商(OPPO、vivo)以及新势力车厂(理想、蔚来)等,在生产中使用 StarRocks。这些企业利用 StarRocks 提升经营效率。
金融行业同样是 StarRocks 的重要应用场景。多家顶级股份制银行(中信、民生、平安银行)、城商行(宁波银行、南京银行、中原银行)以及证券基金公司(广发证券、申万宏源、招商证券)均已在生产环境使用 StarRocks。这些企业利用 StarRocks 降低金融风险、优化投资决策。

不仅在国内,StarRocks 的影响力也在国际舞台上逐步显现。在过去的一年里,多个海外企业通过引入 StarRocks 取得了显著的技术和业务效益:
• 全球最大的图片社交分享网站 Pinterest ,其广告商实时洞察工具 Partner Insights 从 Druid 升级到 StarRocks,实现 P99 延时降低 50%、资源成本降低 68%,性价比提升了 6 倍。
• 东南亚最大的电子商务平台 Shopee ,其核心数据分析产品 DataGO 和 DataService 从 Presto 升级至 StarRocks,查询 Hive 性能相提升 3-10 倍。
• 全球领先的账户类营销平台 Demandbase ,其数据分析平台从 ClickHouse 升级到 StarRocks,计算节点规模减少 60%,存储资源下降 90%。这一显著提升得益于 StarRocks 强大的多表查询能力,用户无需通过复杂的 ELT 构建大宽表。
StarRocks 的应用案例远不止于此。在国际市场,还有许多知名企业在使用 StarRocks,包括零售领域的巨头沃尔玛和屈臣氏、在线旅游领域巨头的 Airbnb、Expedia,以及游戏领领头羊 EAgames、加密货币领域领头羊 Coinbase 等。One more thing,全球市值超万亿美元的企业中已有两家正在使用 StarRocks,充分展示了其在全球范围内的竞争力和影响力。

随着 StarRocks 社区用户越来越多,产生的商业化诉求也越来越多,目前有部分厂商提供 StarRocks 的商业化支持。例如,镜舟科技基于 StarRocks 开发了企业级的镜舟数据库,现已在多个行业成功落地。国内领先的云厂商(如阿里云、腾讯云、火山引擎、华为云和移动云)也在各自的平台上推出了 StarRocks 的托管服务。
此外,许多数据平台和数据中台厂商将 StarRocks 作为数据底座,推动其产品性能提升。例如,瓴羊在其产品中采用 StarRocks 作为轻量化数据底座,帆软 BI 利用 StarRocks 加速 BI 分析,而数势、滴普等企业则通过 StarRocks 支撑用户画像、指标平台等产品的数据分析。
正如 Nvidia Inside 是 AI 时代的核心计算动力,StarRocks Inside 给 BI 数据分析系统提供强大的计算动力。未来,StarRocks 将继续推动生态建设,欢迎更多厂商及数据平台产品使用 StarRocks 驱动业务增长 。

StarRocks 的发展离不开众多厂商和用户的广泛参与和深度支持。这些厂商和用户在使用 StarRocks 的同时,积极参与了社区建设,为其持续发展注入了动力。
作为 StarRocks 社区的主导力量,镜舟科技贡献了 70%+ 的核心功能,包括 CBO 优化器、向量化技术、主键模型等关键特性。云厂商也在 StarRocks 的生态中扮演了重要角色。例如,阿里云、腾讯云和火山引擎深度参与了数据湖分析、物化视图和行列混存等多个功能的开发。与此同时,StarRocks 的用户也通过自身的使用反馈推动了产品的不断完善。例如,腾讯、华为、滴滴、得物和芒果 TV 等企业贡献了文本检索、向量检索和全局字典、K8S Operator 等创新功能。
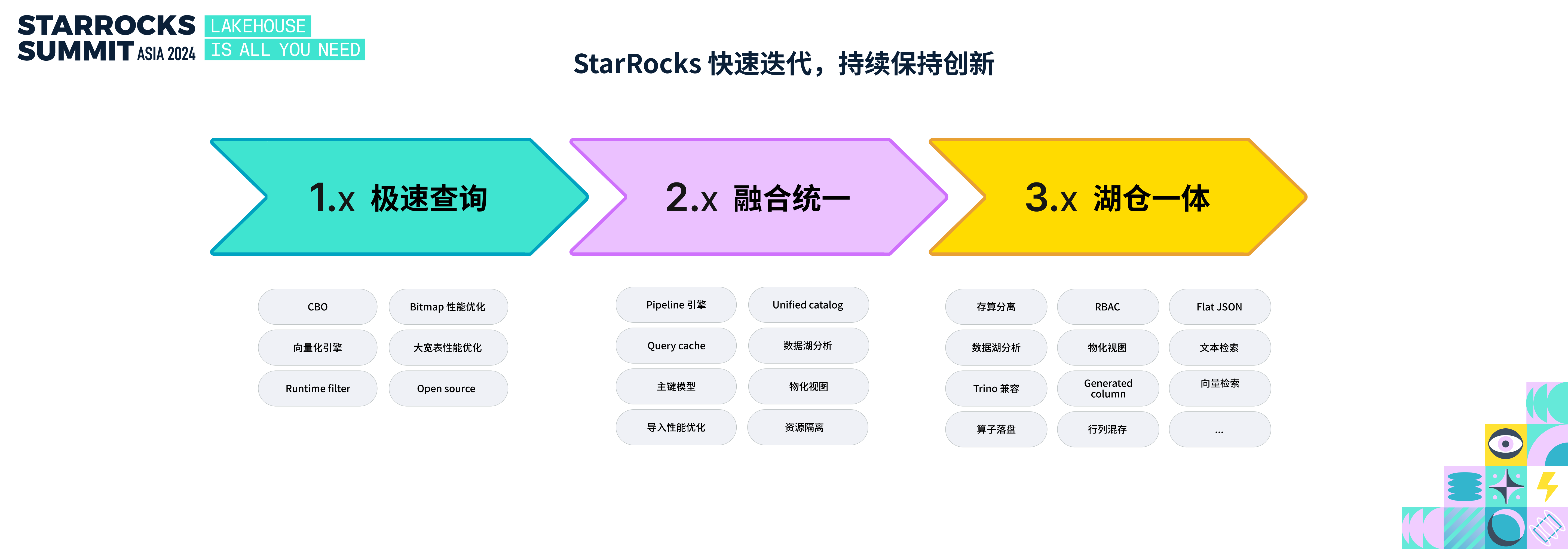
在过去三年,StarRocks 经历了 3 个大版本的迭代,始终保持快速迭代和技术创新,分别是 1.0、2.0 以及现在正在迭代的 3.0 大版本。
1.0 以极速性能为主线,凭借极致的查询性能,在业界企业里开始落地使用。
2.0 以融合统一为主线,能支持更多的应用场景,在企业里不断扩大的使用规模,统一分析技术栈。
3.0 以湖仓一体为主线,希望推动数据分析技术栈向 Lakehouse 方向演进, 推出存算分离架构,物化视图、湖仓分析、半结构化数据分析等一系列的重要特性。
关键技术演进
存算分离

去年 4 月份,StarRocks 3.0 版本正式发布存算分离架构,经过一年半的打磨,存算分离在性能、功能等方面得到全面的提升。
在功能方面,实现了基于对象存储的主键索引,基于存算分离架构也能高效支持实时分析。同时其他的关键功能,例如同步/异步物化视图,generated column、query cache 等,也对齐了存算一体。
在性能方面,热数据查询性能与存算一体一致;引入 SLRU 算法进一步优化 Cache 命中率,避免大查询影响;同时增加 cache warmup 能力,用户可以主动的根据业务需求预热缓存;最后就是不断优化冷查,在标准测试下,完全冷查的开箱性能达到存算一体的 1/3。
在用户方面,目前社区已经有 100+ 用户在生产环境使用了 StarRocks 存算分离,单集群最大规模突破 100 节点。
• 腾讯音乐采用 StarRocks 存算分离替换 ClickHouse、Druid,统一数据分析技术栈,资源成本降低 50%。
• 得物 APP 采用 StarRocks 存算分离替换 ClickHouse,资源成本降低 40%
一句话总结,StarRocks 存算分离是企业降本增效神器,很靠谱,放心用。
实时分析
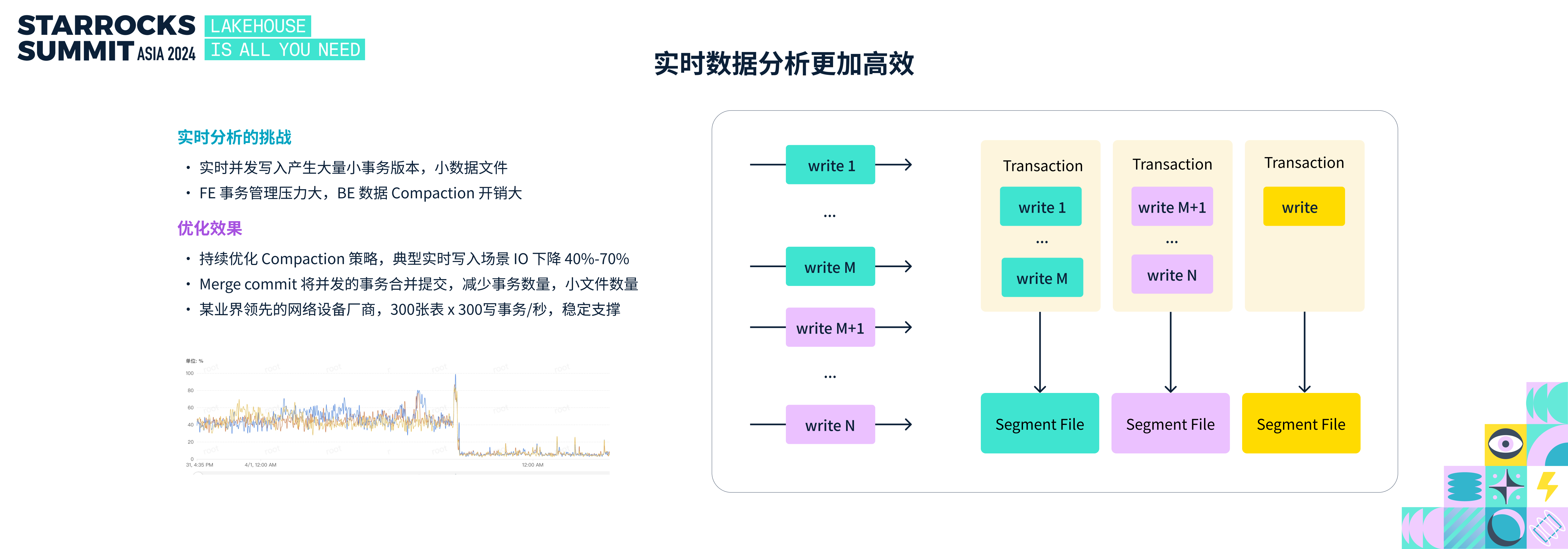
业务对数据分析的实效性要求越来越高,数据实时高并发的写入,产生很多小事务,小文件,给 StarRocks FE 元数据管理带来压力,BE 的数据 Compaciton 也会产生很大的开销。
一方面,StarRocks 主键模型持续优化实时场景 Compacion 策略,在典型的实时写入场景下,I/O 量下降 40%-70%。另一方面,针对实时高并发场景,StarRocks 支持了 merge commit 的策略,将并发执行的多个小事务,合并为大事务提交,从而减少事务数量,减少小文件。
在某国际领先的网络设备厂商的场景中,面对 300 张表、每张表每秒 300 并发的写入场景,StarRocks 能稳定支撑。
半结构化数据
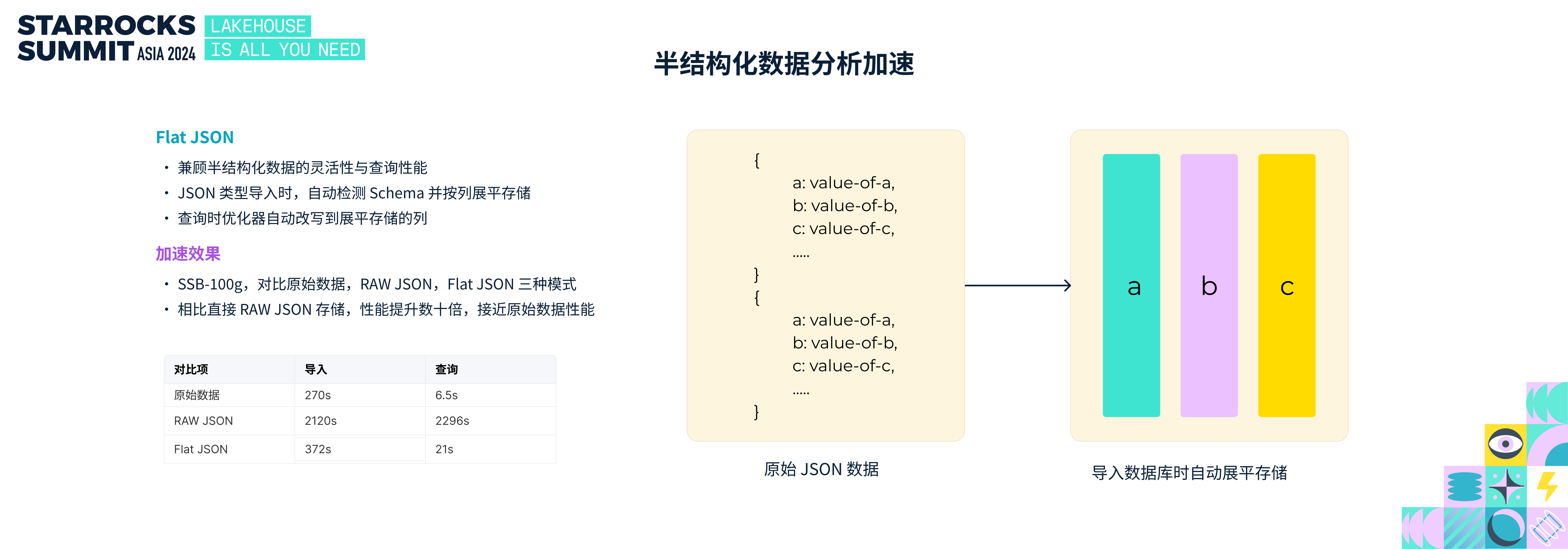
半结构化在数据分析场景越来越普遍,如何兼顾灵活性与查询性能是半结构化数据分析的重要挑战。
StarRocks 3.1 版本里推出了生成列的能力来加速半结构化数据分析,通过将半结构化数据里的指定的列单独存储来提升查询性能,这种方法加速效果好,但用户需要手动指定生成哪些列,不够灵活,不够易用。
于是 StarRocks 推出 Flat json 的能力,针对 JSON 数据列,可以在写入时自动按列展平存储;JSON 展平,相比于按原始数据导入性能有数倍提升,查询性能有数十倍的提升。
向量检索
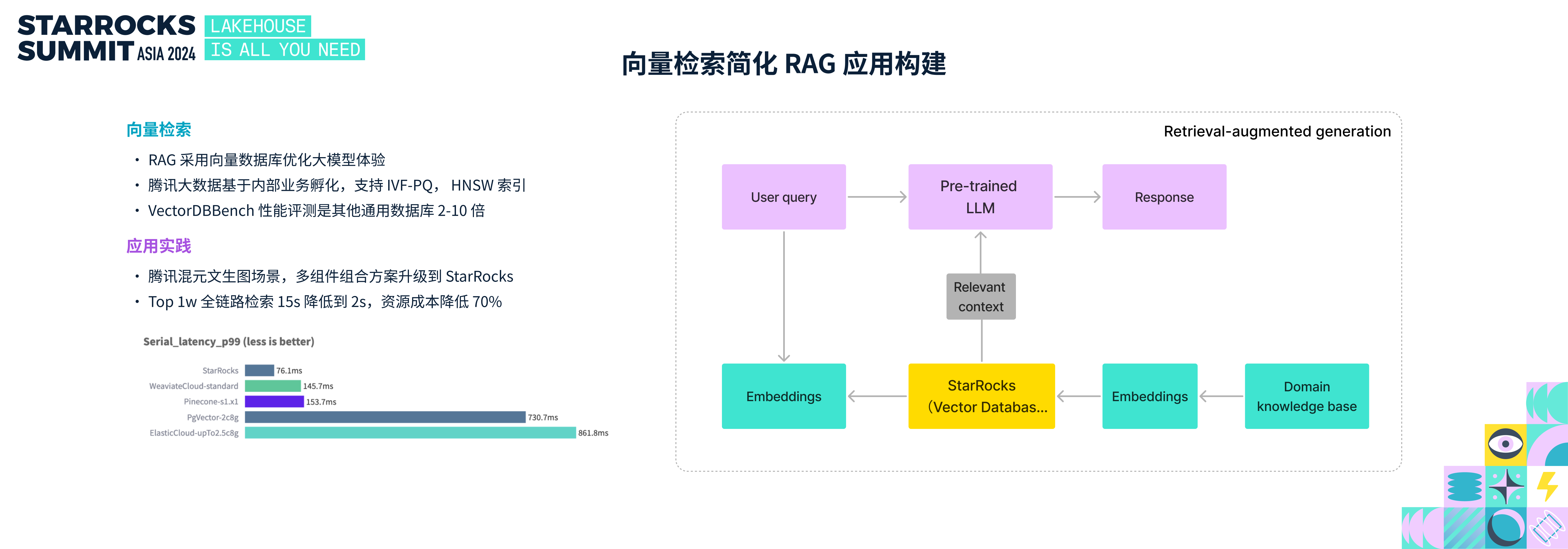
大模型的广泛应用带火了 RAG 应用,RAG 通过将领域知识库存储到向量数据库,用户查询时可以先从向量数据库获取到更多的上下文,然后再将上下文喂给大模型来增强体验。腾讯大数据团队在过去几年内部数据分析场景大规模应用 StarRocks,在今年他们在内部真实的业务场景里孵化出了 StarRocks 向量检索的能力。
StarRocks 向量检索目前支持 ivf-pq、hnsw 两种索引算法,在 VectorDBBench 的性能评测中,相比其他具备向量检索功能的数据库有 2-10 倍的性能提升。
结合腾讯大数据团队之前贡献的文本检索能力,StarRocks 可以支持标量、文本、向量的混合检索过滤,在混元大模型文生图的场景里,StarRocks 相比原有的多组件组合方案,全链路延时从 15 秒降低至 2 秒,资源成本降低 70%。
物化视图
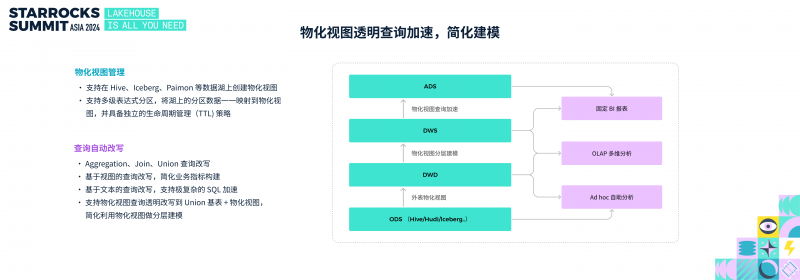
物化视图的加速原理很简单,在数据分析场景中却极具挑战性,主要是因为分析场景中的 SQL 多种多样,既可能由数据库专家编写,也可能由分析师编写,或者程序自动生成。在社区中,已有数百位用户通过物化视图实现了透明查询加速,面对丰富的加速场景,经过多个版本的持续优化,物化视图整体功能已非常完善。
在过去一年里,物化视图的改进主要集中在视图维护与查询加速两方面。物化视图管理上,主要是增强了数据湖上物化视图的能力,支持在 Hive、Iceberg、Paimon 等数据湖上创建物化视图;并支持多级表达式分区,可将数据湖中的分区数据一一映射到物化视图,并提供独立的生命周期管理(TTL)策略。
在自动查询改写上,从基于 Aggregation、Join、Union 的改写扩展到支持基于视图的改写和文本改写,使业务加速更加便捷。另外,StarRocks 还支持查询物化视图自动改写到查询基表,进一步简化基于物化视图的分层建模流程。
湖仓分析

StarRocks 从 1.0 版本便开始支持湖分析的能力。从最初支持 Hive 数据湖,随后扩展到 Iceberg、Paimon 等更多开放数据湖。从支持数据湖分析、数据湖写入、数据湖缓存加速,以及在数据湖上创建物化 MV 等功能,如今,StarRocks 已实现了较为完善的数据湖分析能力。
在性能方面,以查询 Iceberg 为例,StarRocks 查询 Iceberg 的速度是 Trino 的 3-6 倍,同时在查询 Delta Lake 时,其性能是 Databricks Photon 的 2 倍。
Lakehouse Is All You Need
下一个三年,StarRocks 如何“赢”
一切过往,皆为序章。StarRocks 作为一个已经发展三年的开源项目,在这个关键时间节点,我们需要思考一个重要的问题:未来三年,StarRocks 如何在日新月异的数据技术浪潮中保持活力?
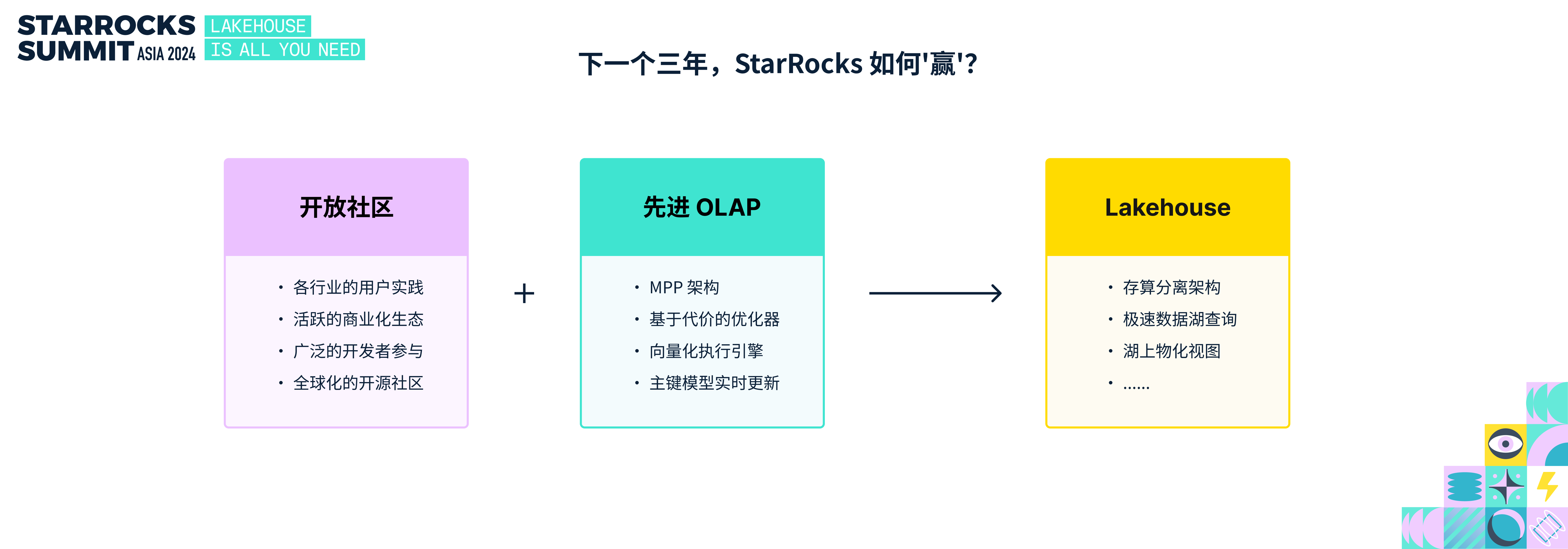
回顾过去三年,如果说 StarRocks 社区还算是取得一些成绩,我认为主要得益于两个关键点:
• 首先是开放的社区。StarRocks 汇聚了广泛的行业用户实践,建立了繁荣的商业化生态,吸引了头部公司的参与和贡献,并逐步走向国际化。这种开放的社区模式,不仅推动了 StarRocks 的技术进步,也让其逐步登上国际舞台。
• 其次是先进的 OLAP 技术。基于代价的优化器、向量化、主键模型等一系列的技术在开源领域都是开创性的,这些技术让 OLAP 变得更加高效和简单。
展望未来三年,StarRocks 将继续保持社区的开放性,但要想始终处于技术前沿并不容易。实际上,在规划 StarRocks 3.0 时,社区已经确定了围绕 Lakehouse 方向的主线。因为我们相信,数据分析的未来属于 Lakehouse。这也是今天分享主题 “Lakehouse is all you need” 的由来。这个标题灵感源自 AI 领域家喻户晓的论文 《Attention is all you need》,它阐述了注意力机制对 AI 的重要性,而 Lakehouse 对数据分析的重要性就如同 Attention 之于 AI。
至于为什么 Lakehouse 对数据分析如此重要,我们还需追溯到 1980 年代的数据技术变革。
数据分析架构演进与挑战
数据仓库 vs 数据湖
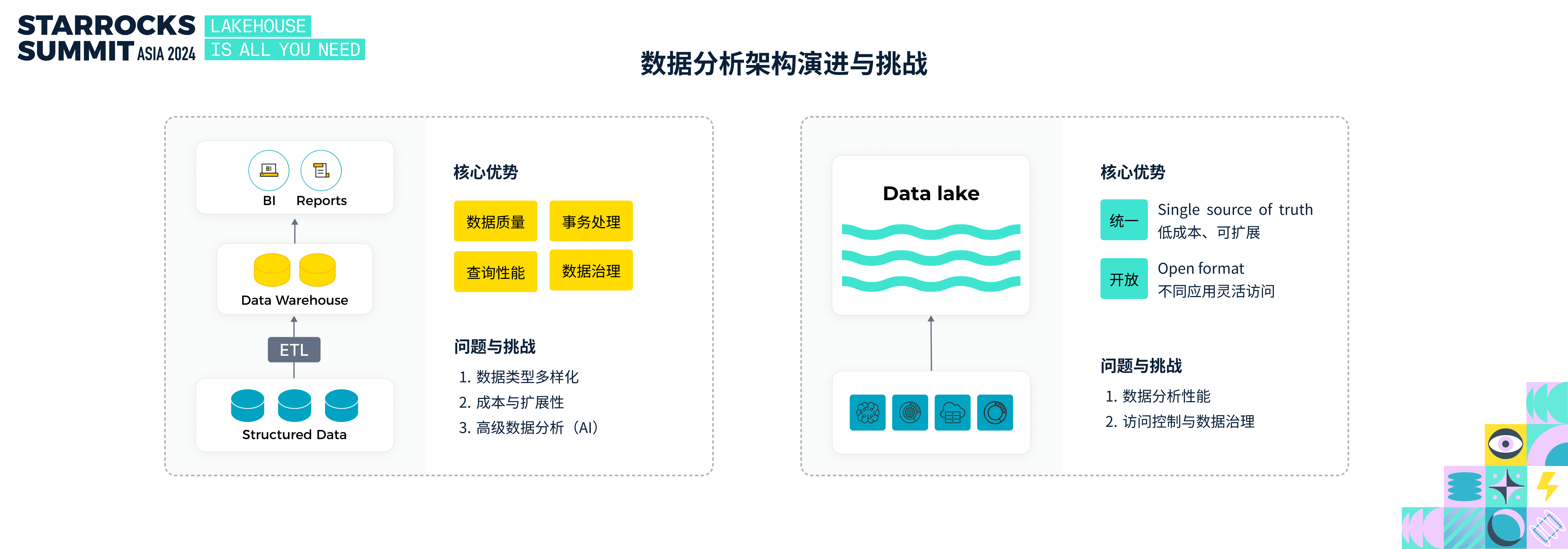
数据仓库的发展可以追溯到 1980 年代。当时,通过 ETL 处理将关系型数据库、日志文件等数据源的数据统一存储到数据仓库,用于支持 BI 报表、数据挖掘等分析场景。数据仓库在数据质量、事务处理、查询性能和数据治理等方面具备显著优势。然而,随着数据量的激增和分析需求的日益复杂,传统数据仓库也面临以下挑战:
• 数据多样化:除了结构化数据,半结构化和非结构化数据越来越多。
• 成本与扩展性:大数据量增长带来了存储成本的压力和横向扩展的问题。
• 高级数据分析支持:新兴 AI 应用难以高效访问数据仓库中的数据。
2010 年,数据湖的概念首次提出。如果将数据仓库比作经过加工处理的瓶装水,那么数据湖更像一个原生态的大池子,企业可将不同类型的数据统一存储于此。数据湖的核心优势在于其统一性和开放性:
统一性:提供低成本、高扩展性存储,成为企业数据的 Single Source of Truth
开放性:采用开放的数据格式,方便不同应用灵活访问。
虽然数据湖在存储层面解决了数据仓库的诸多问题,但新的挑战也随之而来:如何挖掘数据湖中的数据价值?应用该如何高效地使用这些数据?
数据湖、数据仓库分层组合架构
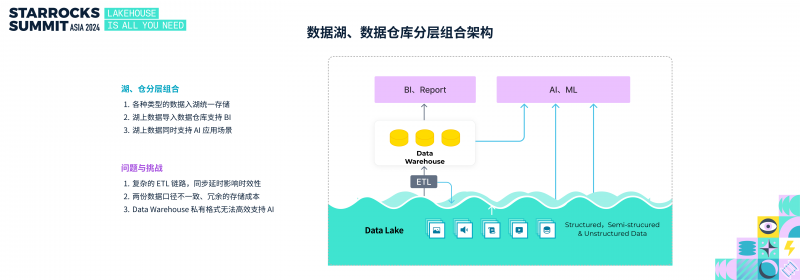
业界为应对上述挑战,提出了一种数据湖与数据仓库分层组合的架构:
• 各类数据统一存储到数据湖中
• 数据湖中的数据被导入数据仓库,用于支持 BI 数据分析
• 数据湖中的开放格式数据直接支持 AI 应用场景
这一架构非常普遍,可以说目前绝大多数企业都采用了类似的方案。其中,Hadoop + OLAP 数据库的组合是经典代表。然而这种组合也存在明显问题:
• 复杂的 ETL 链路,数据同步延时影响实效性
• 两份数据口径不一致、冗余的存储成本
• Data Warehouse 私有格式无法高效支持 AI
Lakehouse 是下一代数据分析架构的标准
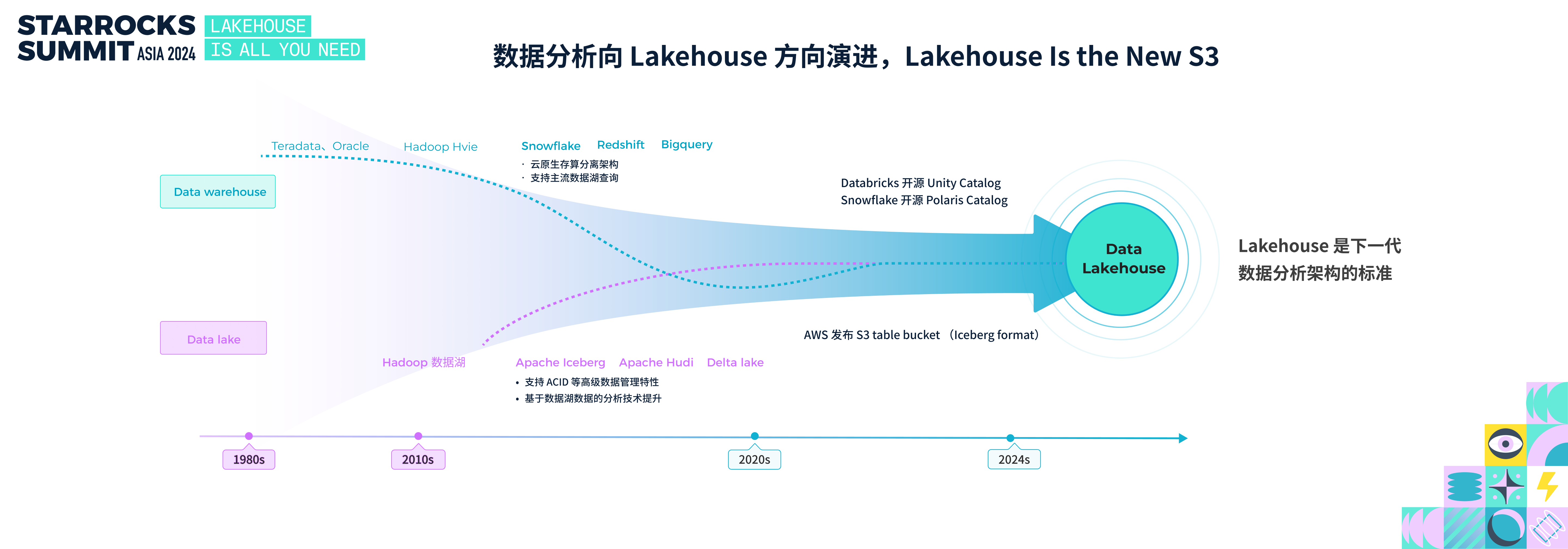
过去十多年里,分层架构得到了广泛应用。在不断发展的过程中,数据湖与数据仓库也在不断突破边界,加速了两者的融合。
从数据仓库的演进来看,新兴的数据仓库(如 Snowflake、Redshift、BigQuery)普遍采用云原生的存算分离架构,并且支持直接查询开放数据湖的能力。与此同时,随着新兴数据湖格式(如 Iceberg、Hudi、Delta Lake)的发展,数据湖的事务支持能力显著提升,在性能方面,通过优化数据分布、引入缓存机制等技术,数据湖的分析性能也得到了大幅改善。
2024 年,Lakehouse 的发展更是迎来了重要的里程碑:Databricks 收购 Tabular,并开源 Unity Catalog;Snowflake 开源 Polaris,争相抢占 Lakehouse 的入口。另外,就在三天前的 AWS reinvent 大会上,AWS 发布了 S3 Tablet Bucket,采用了 Iceberg 的开放格式。种种迹象表明,Lakehouse 的时代已经到来。
Lakehouse 是什么?
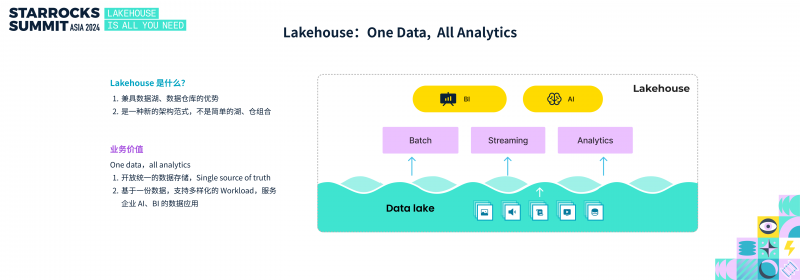
到底什么是 Lakehouse?顾名思义,Lakehouse 结合了数据湖与数据仓库的优势。2007 年,苹果推出革命性的智能手机 iPhone。iPhone 同时具备了 iPod、电话和网络浏览器的功能,但它不仅仅是这些功能的集合,而是一个具备革命性用户体验的新产品。同样,Lakehouse 也不是数据湖与数据仓库的简单组合,而是一种全新的架构范式。
Lakehouse 通过融合数据湖与数据仓库的优势,能实现 “One Data, All Analytics” 的业务价值。构建 Lakehouse 后,你将拥有:
• 开放统一的数据存储
• 基于一份数据,支持多样化的 workload,服务企业 AI、BI 的数据应用
如何构建 Lakehouse?
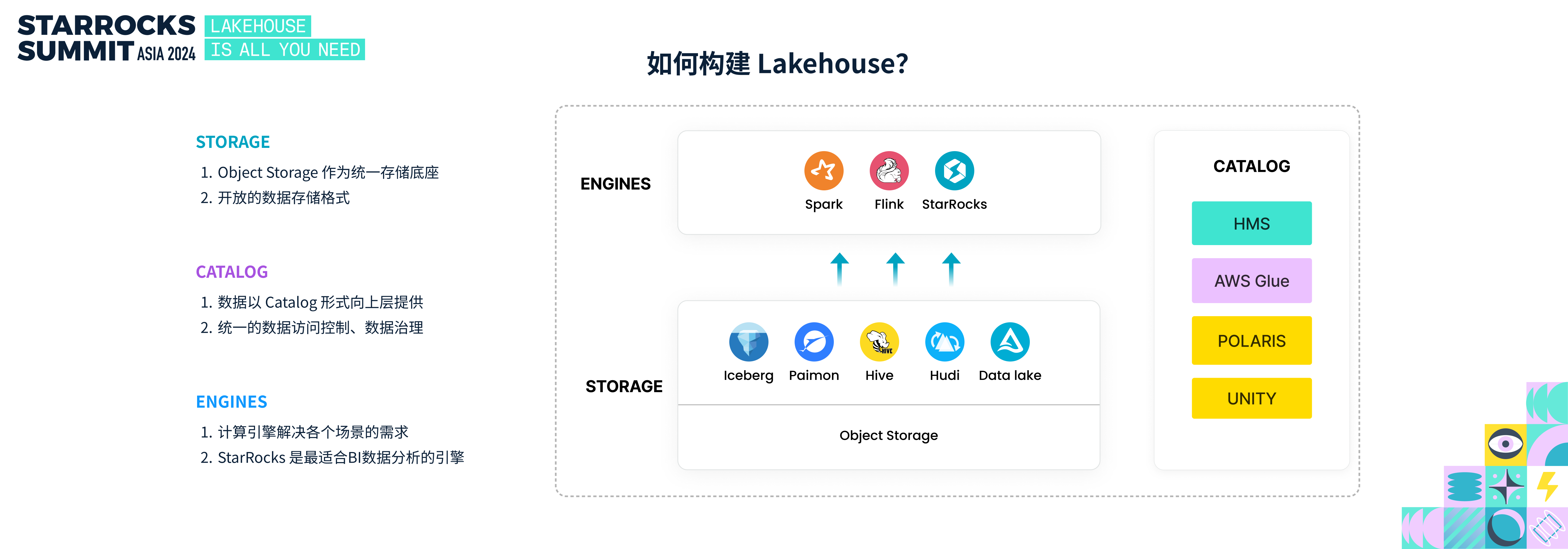
那么,如何构建 Lakehouse 呢?Lakehouse 数据分析架构的核心由三个关键元素组成:存储、Catalog 和计算引擎。
1. 存储:Lakehouse 通常以低成本的对象存储作为数据底层,数据以开放格式存储。目前流行的湖格式包括 Iceberg、Paimon、Hudi、Hive 和 Delta Lake。其中 iceberg 因其开放性、Paimon 因其实时的理念,在业界备受关注,是构建 Lakehouse 的首选。
2. Catalog,湖上的数据统一以 Catalog 的方式呈现,这样便于数据的统一管理,方便数据的访问、共享与治理,当前流行的 catalog 包括 HMS、AWS Glue Catalog 、Snowflake 开源的 Polaris Catalog、Databricks 开源的 Unity Catalog。从当前趋势看,业界正在逐步往 REST Catalog 方向演进。
3. 计算引擎,计算引擎直接基于湖上的数据完成计算任务,服务不同等应用场景;当前 StarRocks 是数据湖上最适合 BI 数据分析的引擎。
基于 StarRocks 构建 Lakehouse

接下来我们聚焦到 StarRocks,探讨如何基于 StarRocks 构建 Lakehouse,只需三步:
1. 选择开放的数据湖作为底座,例如 Iceberg 、 Paimon;
2. StarRocks 直接分析湖上的数据,满足绝大部分场景的性能诉求;
3. 如果分析性能不满足要求,则基于数据湖创建物化视图加速。
我们来对比一下,这种范式与前面提到的分层架构相比,带来了哪些本质变化:
1. 从 Data Pipeline 角度,分层架构需要 ETL job 同步数据;lakehouse 方案无需维护 ETL job。
2.从 Data Freshness 角度,分层架构需要等待数据同步时间,影响时效性;而 lakehouse 的方案,入湖即可查。
3. 从 Data Reliabity 角度,分层架构两份数据,容易总成口径不一致;而 lakehouse 是基于湖上的数据作为 single source of truth
4.从 Data Cost 角度,分层架构会带来数据冗余存储,而 Lakehouse 只需要湖上的一份存储。
Lakehouse 获得数据仓库的查询性能
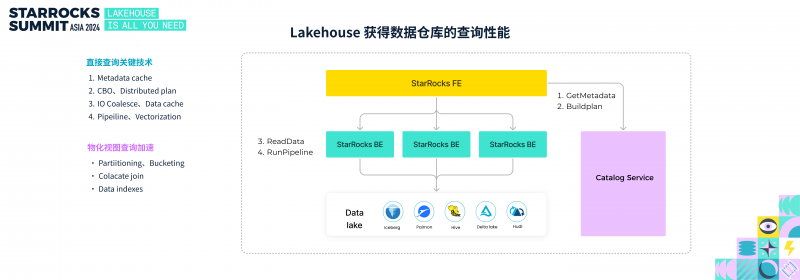
Lakehouse 方案优势明显,但其能否在数据湖上实现媲美数据仓库的查询性能,是一个核心挑战。毕竟,如果在数据湖上的查询足够高效,企业自然更愿意避免复杂的数据迁移与维护流程。
StarRocks 查询湖上查询通常分为以下几个阶段:获取数据湖元数据、构建执行计划、读取数据,并完成整个执行 Pipeline。每个阶段 StarRocks 都开发了相关的技术来让湖上查询变得更加高效,包括元数据缓存、CBO、分布式执行计划、I/O 合并、数据缓存、向量化执行等。同时 StarRocks 还支持在数据湖上创建物化视图,利用 StarRocks 细粒度分区分桶、Colacated join、丰富的索引能力进一步加速查询。
通过上述关键技术,使得 StarRocks 直接查询数据湖时实现媲美传统数据仓库的性能,基于 StarRocks 构建 Lakehouse 的方案已经在业界被广泛实践。
StarRocks x Iceberg 构建 Lakehouse
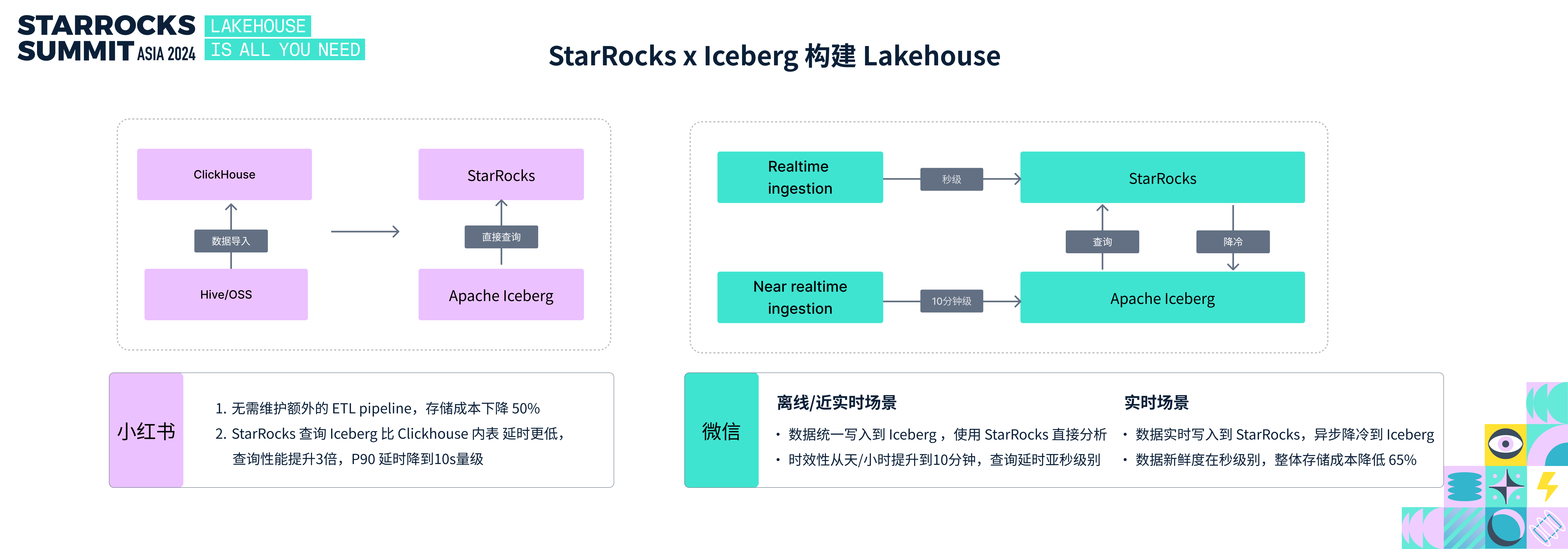
小红书的 REDBI 系统最初采用 ClickHouse,通过 ETL 将 Hive 和 OSS 的离线数据导入 ClickHouse 提供查询服务。今年,他们成功升级为 StarRocks + Iceberg 的 Lakehouse 方案。无需再维护复杂的 ETL 流程,存储成本下降 50%,借助湖上数据 zorder 排序等技术,P90 的延时下降到 1/3,达到 10s 量级。
微信基于 StarRocks 和 Iceberg 构建 Lakehouse 架构。在离线和准实时场景中,他们选择将数据写入 Iceberg 作为统一存储,通过 StarRocks 直接分析,实现了数据新鲜度从天/小时级别提升到 10 分钟级别,查询延时则优化到了亚秒级。在秒级实时场景中,由于 Iceberg 无法支持秒级实时写入,他们将数据写入 StarRocks 以实现实时分析,并异步降冷至 Iceberg 统一存储;既满足了秒级新鲜度的需求,整体存储成本降低 65%。
StarRocks x Paimon 构建 Lakehouse
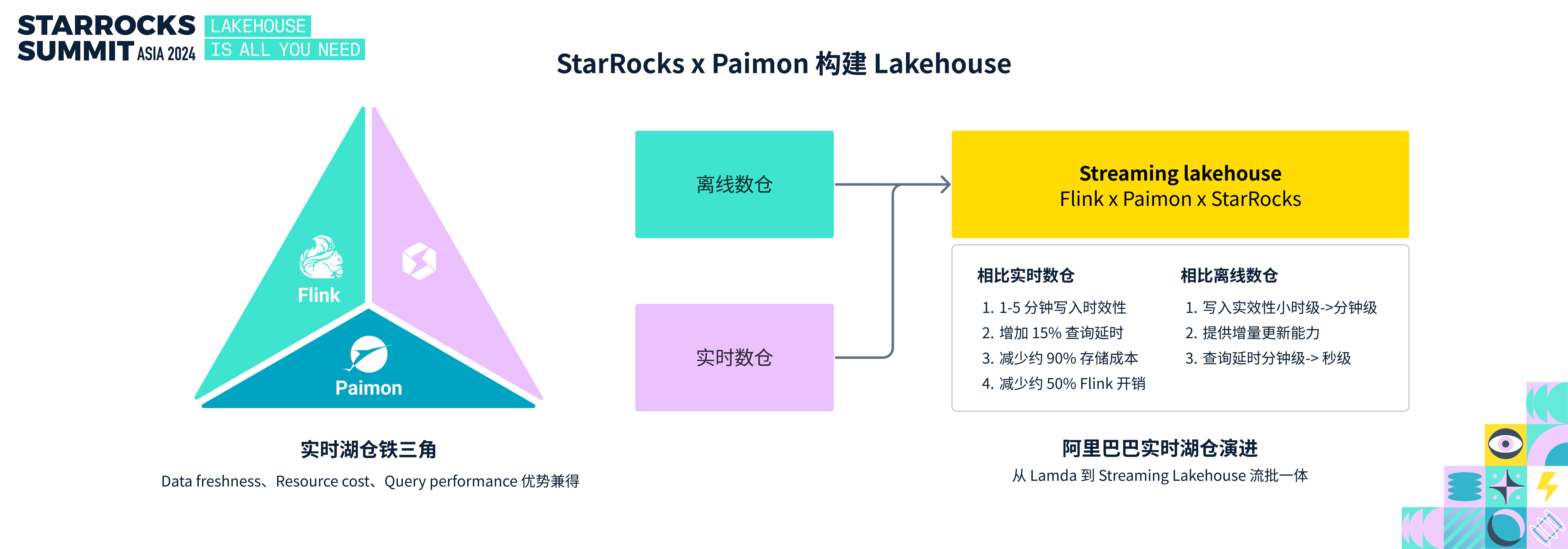
在数据分析领域有一个不可能三角——数据新鲜度、资源开销和查询性能三者不可兼得。然而,Flink + Paimon + StarRocks 的实时湖仓铁三角,正在逐步突破这种不可能,使得用户在新鲜度、资源开销、查询性能上获得一个很好的平衡。
1. 通过 Flink 保证数据的实时处理并写入到数据湖。
2. Paimon 基于对象存储获得低存储成本。
3. StarRocks 查询 Paimon 数据获得高查询性能。
在上周结束的 Flink Forword 大会上,已经有很多企业实践了实时湖仓范式,包括阿里巴巴,喜马拉雅,同程旅行,vivo 等众多企业。阿里巴巴从传统的离线数仓 + 实时的 Lambda 架构,演进为 Flink + Paimon + StarRocks 的实时 Lakehouse 方案,在饿了么的业务中,已经充分体现了这个方案的价值:
相比实时数仓:写入时效性提升至 1-5 分钟范围;查询延时仅增加 15%;存储成本减少约 90%;同时 Flink 计算开销减少约 50%。相比离线数仓:写入时效性从小时级缩短至分钟级。支持增量更新能力实现流批一体;查询延时从分钟级降至秒级。
总结
回到今天的主题——Lakehouse is all you need。
• 对于数据工程师:无需维护复杂的 ETL Pipeline
• 对于数据分析师:可以实时高效地在数据湖上进行探索和分析
• 对于数据科学家:直接访问数据湖上的开放数据,构建 AI 应用
• 对于企业的经营管理者:通过简单高效的数据分析,实时推动企业经营决策
Lakehouse 的确拥有非常大价值,而 StarRocks 作为最适合 BI 数据分析的 Lakehouse 引擎,可以让数据湖中的数据高效地转化为价值。Lakehouse is all you need, StarRocks will power it!
最后,特别感谢每一位用户和开发者,感谢你们为 StarRocks 社区的每一条问题反馈、每一个 PR,以及每一次布道活动。正是你们的努力,使得 StarRocks 不断成长和进步。我们也希望在社区的陪伴下,StarRocks 能为大家的公司带来业务增长,同时助力个人实现技术成长。
让我们携手共进,共同见证 Lakehouse 的发展浪潮。
免责声明:市场有风险,选择需谨慎!此文仅供参考,不作买卖依据。
责任编辑:kj005
文章投诉热线:157 3889 8464 投诉邮箱:7983347 16@qq.com











