中华网家电
设为书签Ctrl+D将本页面保存为书签,全面了解最新资讯,方便快捷。
评标作为采购运营的重要一环,其效率与准确性直接关系到企业的竞争力和市场响应速度。然而,从海量标书收集整理,到逐一审阅打分,每一个环节都离不开人力密集型操作。这不仅导致效率低下,还容易因人为误差,影响评审结果的公正性。
那么,借助时下大火的通用大模型,帮助企业、评标专家智能分析并生成评标报告,可行吗?理想很丰满,现实太骨感。
通用大模型与B端所需的精准答案“相悖”
与C端不同,B端场景下的大模型,不再是一个简单的问答机器,需要变成强大的业务逻辑处理器,它必须理解和处理复杂行业、应用场景的特定语境,给出深度和精准的答案。
而大模型推理的精准度,高度依赖“被投喂”的训练语料。在B端,企业通常拥有大量、私有的事实性知识,很多知识还是企业核心资产。通用大模型无法对上述知识数据“抓取”分析,就会导致事实性偏差、胡说八道急剧上升。
具体到采购评标场景,不同采购人、采购项目选择供应商的标准差异巨大,有的资质占比大、有的履约分量重。如果用通用大模型来做决策,就会导致“不同采购项目,同一判断标准”“同一项目,多次询问,结果不一”等现象。“稀里糊涂”“模棱两可”在企业采购场景下,是不可接受,甚至是致命的。
大模型用于采购评标,法官VS律师?
因此,想要将大模型应用于采购评标,就需要借助采购垂直领域行业大模型,前期对大量的招标、投标文本进行深度学习,并依靠人工采集和标注的方法,不断校正偏差,才能确保其在该领域的专业度和精准度。
由于任何一个大模型都是人工训练出来的,即便是采购行业大模型,用在评标中,也做不了“法官”,只能做“律师”,像律师一样提供证据链和建议的结果,这个结果一定要是可解释的,是有过程的,最终让法官(评标专家)去决策。
北京筑龙研发的智能评标系统,就是基于上述理念而研发的。系统基于自然语言处理(NLP)、OCR等技术,用AI承担招投标文件的内容提取、分析比对、自动定位等工作,专家借助AI给出的数据链和比对结果,快速给出准确结论。
智能辅助评标,让评标更简单、也更高效
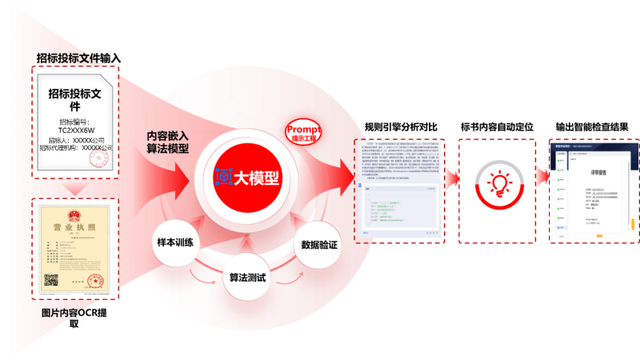
AI解析标书,快速定位关键项。智能评标系统,能够对评标点、应标点进行结构化解析,建立比对分析的阅读导航,并支持关联定位原文位置,快速回溯决策;不论是文本、图片,还是表格,都能识别分析。让智能辅助评标,真正实现“无盲区”“无盲点”。
智能清标,“一键”批量检查。系统可以对标书中的客观信息(企业规模、资质、信誉、财务状况等)进行符合性比对,筛出“硬件”不符的投标方;资料缺失、内容前后不一致、不满足评标要求等,系统也都会“高亮”提示;此外,系统还能自动生成评标分析报告,标书合格与否、原因如何,直观呈现,为专家评标提供客观依据。
围串标分析,让专家“自由裁量权”有据可依。系统能够对两份或两份以上投标文件进行围串标鉴定,分析投标人的关键信息、股权关系、上传/下载IP地址、设备MAC码、造价锁等软硬件指标,全方位鉴别围串标风险;即便在投标文件在形式、顺序、格式上做了调整,也能被识别出来。值得注意的是,对标书进行雷同性检查时,系统会自动过滤“来自投标文件中的标书内容”,如通用承诺、审计报告等,避免围串标审查“误伤”合规标书。专业精准的围串标分析,既帮助专家快速找到“问题标书”,也能平衡专家“自由裁量权”,让采购评标更客观合规。
责任编辑:kj005
文章投诉热线:157 3889 8464 投诉邮箱:7983347 16@qq.com












