中华网家电
设为书签Ctrl+D将本页面保存为书签,全面了解最新资讯,方便快捷。
黄仁勋掀翻AI PC,但DGX Spark的硬伤藏不住了
2026年6月1日,COMPUTEX台北,黄仁勋用一场两小时的演讲宣告AI PC时代到来。RTX Spark超级芯片正式发布——1 PetaFLOP算力、128GB统一内存、可本地运行1200亿参数大模型,宏碁、华硕、戴尔、惠普、联想、微软、微星七大厂商将于今秋推出首批机型。老黄称之为“自Windows 95以来PC最彻底的重新发明”。
但对于真正搞AI开发的工程师和研究者来说,他们手里的“心头好”并不是RTX Spark,而是 NVIDIA DGX Spark——搭载GB10超级芯片的桌面级AI超算,拥有同等1 PetaFLOP算力,但软件栈更完整(DGX OS + vLLM + NIM + NeMo),支持200B甚至405B参数模型的本地开发。
然而,DGX Spark有一个被严重低估的致命短板:本地NVMe存储只有4TB。
4TB的“存储墙”:KV缓存几小时写满,首Token要等187秒
AI推理最耗时的环节不是生成Token,而是预填充(Prefill)。每一次请求都要完整计算输入上下文的KV缓存。在长文档RAG、多轮智能体对话等场景中,相同上下文被反复计算,GPU算力大量浪费。
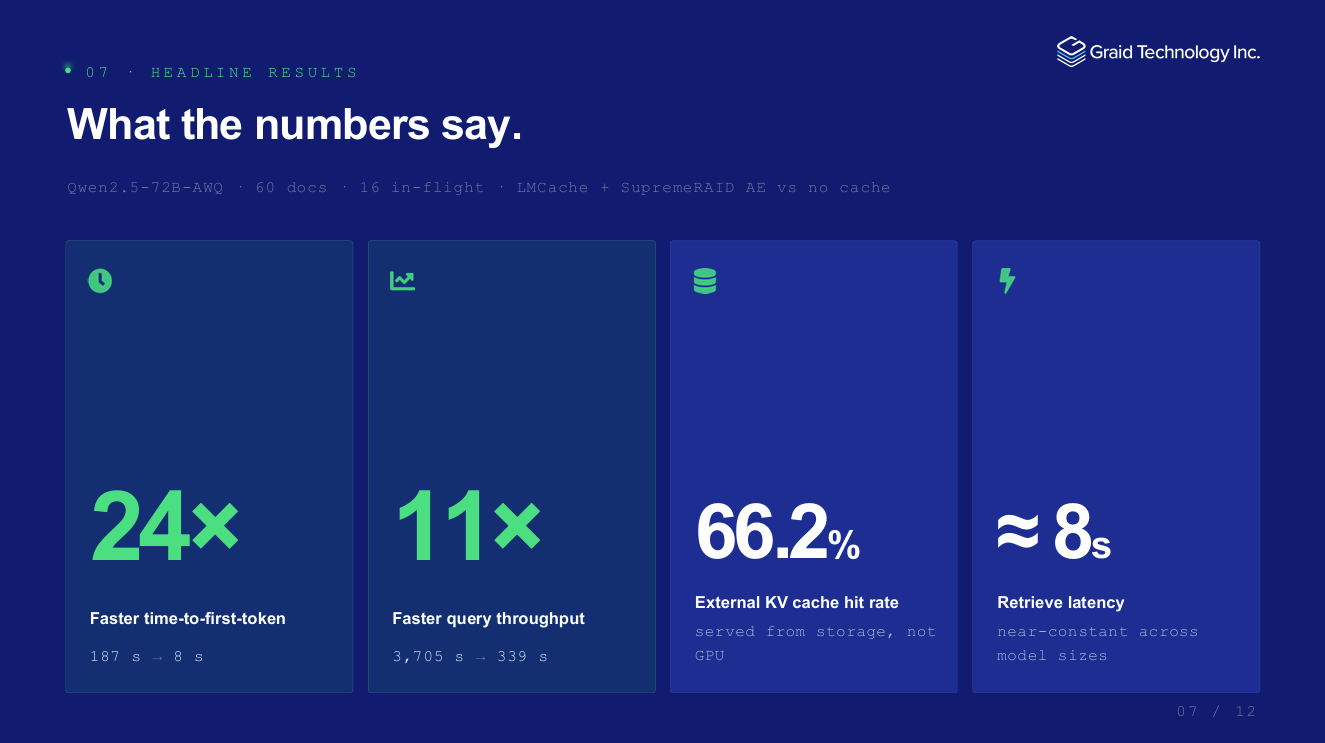
实测数据触目惊心(Qwen2.5-72B-AWQ,60篇文档,16路并发):
首Token时间(TTFT):187秒——用户泡杯咖啡回来还在等
单轮完整查询:3705秒——超过一小时
4TB空间很快写满 → 系统被迫驱逐旧缓存 → 重新预填充 → 恶性循环
DGX Spark缺的不是算力,而是一个专为KV缓存设计的、带RAID保护、延迟接近本地NVMe的外部存储层。
绿算GP Spark:专为Spark类AI PC打造的“计算型外挂”
绿算技术(Luisuan Technology)在COMPUTEX 2026现场给出了答案:GP Spark计算型存储节点。
核心亮点:
超紧凑NVMe-oF目标器,为DGX Spark扩展最高64TB KV缓存池
NVMe-oF + RoCEv2协议栈全硬件卸载,DGX Spark主机端CPU零占用
100GbE RDMA直连,内核旁路DMA,数据路径不走CPU
只需加载标准nvme-rdma驱动,即插即用

一句话总结:DGX Spark存储的事GP Spark全包了。
Graid SupremeRAID™ AE:给KV缓存上“保险”
光有大容量还不够,企业级场景还需要数据保护。联手登场的是Graid Technology——GPU加速RAID领域的先锋。
SupremeRAID™ AE在DGX Spark + GP Spark方案中提供三重价值:
① 零CPU/GPU占用
传统软件RAID(mdadm/ZFS)做RAID 5/6会大量吃掉CPU,而SupremeRAID™ AE将所有条带化、奇偶校验计算卸载到专用硬件引擎,主机CPU和GPU零占用。1 PetaFLOP算力,100%留给模型。
② 企业级RAID保护
支持RAID 0/1/5/6/10,容忍单盘或多盘故障。一块SSD坏了,KV缓存数据不丢,不用痛苦地全量重预填充。
③ 无缝集成NVMe-oF
将GP Spark暴露的独立NVMe子系统虚拟化为单一RAID保护逻辑卷,对vLLM、LMCache完全透明——零代码修改。


三者闭环:GP Spark提供硬件卸载存储 → SupremeRAID™ AE提供GPU加速RAID → 标准NVMe-oF协议无缝对接。这就是“计算+存储+保护”的完整方案。
完整方案:从算力到存储,一栈式优化
软件栈:
推理框架:vLLM 0.21.0(连续批处理 + 原生前缀缓存)
缓存管理:LMCache 0.4.5(透明卸载KV缓存至远端,无需改模型)
存储访问:NVMe-oF / RoCEv2 RDMA直连GP Spark
RAID层:SupremeRAID™ AE(RAID 5/6/10)
硬件连接:一台GP Spark通过100GbE线缆直连一台DGX Spark,无需交换机,最小化延迟与故障点。支持GPU Direct Storage——数据从GP Spark的SSD直达GPU显存。
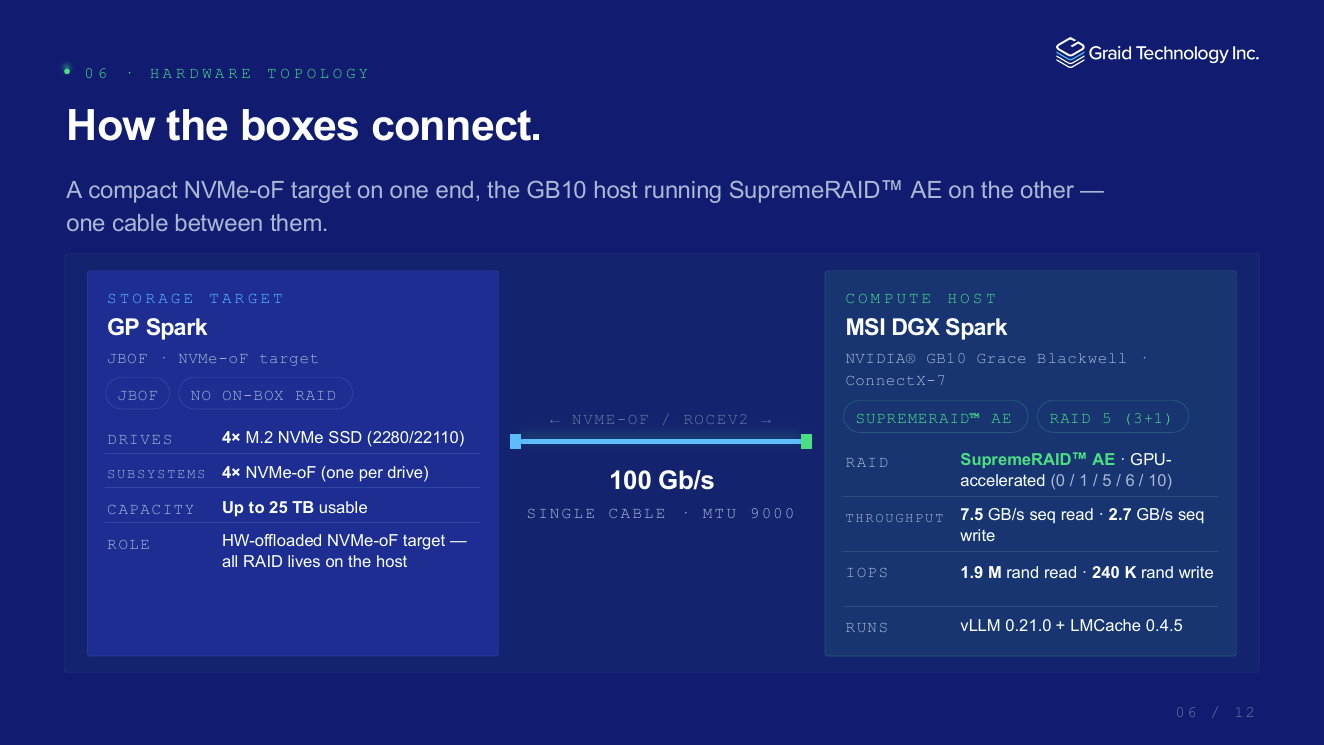
真实数据:从187秒到8秒
同样的测试环境(Qwen2.5-72B-AWQ / 60篇长文档 / 16路并发),接入GP Spark + SupremeRAID™ AE后:
首Token时间(TTFT):从187秒 → 8秒,加速23倍
单轮完整查询:从3705秒 → 560秒,加速6.6倍
多轮对话(3轮):从11115秒 → 2130秒,加速5.2倍
关键洞察:每次从GP Spark恢复KV缓存的耗时固定约8秒,不随模型增大而增加。模型越大,冷启动预填充成本越高,相对收益越显著——70B以上模型可获20倍以上加速。

远程存储?延迟会不会高?
这是开发者最常问的问题。答案是:几乎无感。
三重技术保证:
NVMe-oF + RoCEv2 100GbE RDMA直连,远程读取延迟与本地NVMe差异仅约6%
SupremeRAID™ AE零CPU占用,不抢算力
专属直连架构(一对一),无交换机延迟抖动
你用起来是本地NVMe的延迟体验,得到的是企业级存储的容量和可靠性。
谁最需要这套方案?
长上下文RAG开发:金融、法律、科研领域的文档检索与问答
多轮智能体(Multi-Agent):AI助理、客服机器人、编程助手——需要长期记忆
批量重复提示分析:同时处理大量相似prompt
多模型/多会话并发:一机服务多用户
记住一句话:模型越大、上下文越长、并发越高,GP Spark + SupremeRAID™ AE的收益越显著。
从单机到集群:GP Spark 3000已在路上
目前GP Spark采用“一对一”直连架构。未来,绿算技术已规划GP Spark 3000系列交换存储平台,支持最多8台DGX Spark共享存储资源,通过RDMA与GPU Direct Storage实现内核级无缝集成——让个人AI工作负载从单机走向集群。
关于绿算技术 & Graid Technology
绿算技术(Luisuan Technology)致力于为AI大模型时代提供高性能、可扩展的智能存储解决方案,产品涵盖智能存算一体机、高性能NVMe-oF扩展柜,旨在打破算力“内存墙”与“IO瓶颈”。
Graid Technology Inc. 是GPU加速RAID技术的先锋,SupremeRAID系列通过创新GPU卸载架构,为NVMe SSD提供极致性能释放与数据保护,广泛应用于AI、HPC及企业级关键任务场景。
免责声明:市场有风险,选择需谨慎!此文仅供参考,不作买卖依据。
责任编辑:kj015