中华网家电
设为书签Ctrl+D将本页面保存为书签,全面了解最新资讯,方便快捷。
1月15日,科大讯飞发布了当前全国产算力平台上唯一的深度推理模型——讯飞星火X1。3月3日,星火X1迎来升级,数学能力全面对标DeepSeek R1和OpenAI o1,显著提升竞赛级难题应对能力及中小学数学作业批改、辅导等任务表现。同时,首发星火医疗大模型X1,并推出包括星火一体机在内的系列新品。
科大讯飞在官宣中表示,升级后的星火X1之所以会在数学能力上有突破性进展,主要是该版本采用了两大创新技术。
一是通过高效的领域数据自动化挖掘和多类型数据合成算法,构建了海量的数学领域预训练数据,从而显著提升了基座模型的数学专业能力;
二是基于评语模型与强化学习算法,实现了大模型长思维链的激发,同时评语模型还促使大模型在推理过程中进行反思验证,进一步提升了模型在推理阶段的准确性。
那么,这款升级后的星火X1是否真如科大讯飞所说,在数学能力方面可全面对标在业内以推理著称的DeepSeek R1?下面我们就来做一个简单评测。
为保证测试公平性,两款大模型均以首次生成的答案为准。
测试题为《2024年山东省济南市中考数学试卷》中的解答题,8个小题,共72分。为确保输入正确,每题均先截图,然后由两大模型识别图片中的字符并解答。
这一方法,除了能检验两大模型的解题能力外,还能验证其OCR识别能力。毕竟对于数学、物理、化学等学科来说,图形、公式、符号是常态,用键盘输入的方式很难完成。如果OCR识别能力差,无法正确识别文字、字符、公式、图片,不仅会极大影响大模型的解题正确率,同时也会令其适用场景变窄,如无法赋能字纸作业和试卷等。
试题1:
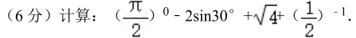
星火X1解答如下:

DeepSeek R1解答如下:

该题分值为6分,正确答案是4,星火X1回答正确得6分,DeepSeek完美答错,答错原因,应该是DeepSeek在识别图片中的字符时,误将“-Sin30°”当成π/2次方数的一部分了。
试题2:
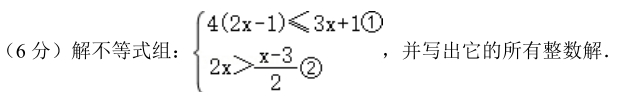
星火X1解答如下:

DeepSeek R1解答如下:

该题DeepSeek R1犯了与第一题类似的毛病,字符识别不正确,误把3x+1①识别成了3X+10,最后导致答案错误。该题满分6分,星火X1回答正确,得6分。
试题3:

星火X1解答如下:

DeepSeek R1解答如下:

该题两大模型完美回答,各得6分。
试题4:


星火X1解答如下:

DeepSeek R1解答如下:

两大模型全部答对,各得8分。
试题5:

星火X1解答如下:

DeepSeek R1解答如下:

两大模型完美地解决了该问题,各得10分。
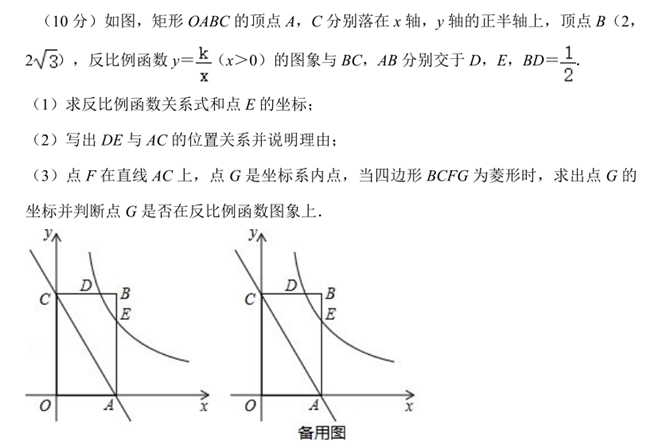
试题6:
星火X1解答如下:

DeepSeek R1解答如下:

星火X1完全答对,得10分;DeepSeek R1基本答对,只是在解答最后一个问题时,忽略了F点有可能在点C的上方这一事实,只考虑到了当G点在点F右方这一种情况,因此少给了一个坐标。按本大题满分10分,前两小题比较简单,各占三分,最后一小题占4分来打分,DeepSeek R1本题得分8分。
试题7:

星火X1解答如下:

DeepSeek R1解答如下:

星火X1三个小题均给出了正确答案,只是解题过程过于笼统,扣1分,该题满分12分,得11分。DeepSeek R1解题过程相对详细、明了,但最后一小题答错了,扣4分,得8分。
试题8:
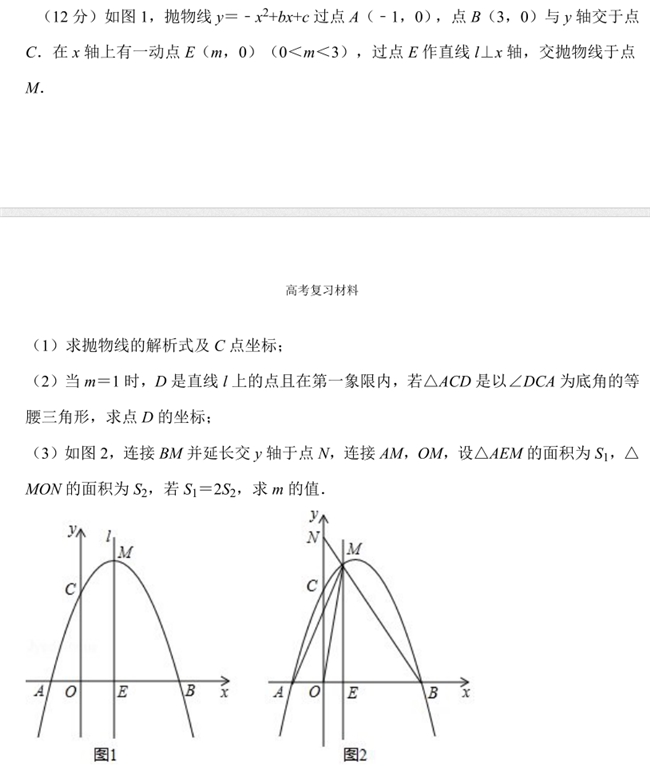
星火X1解答如下:

DeepSeek R1解答如下:

两大模型回答基本正确,只是在解答2小题上,都忽略了其实还有一种情况,那就是AC=AD,当AC=AD时,点D还应该存在一个坐标,即(1,√6);本题满分12分,以每小题4分计,各扣2分,最终两大模型得分均为10分。
小结:
最终两大模型考试成绩见下表:
两大模型成绩汇总(满分:72分)
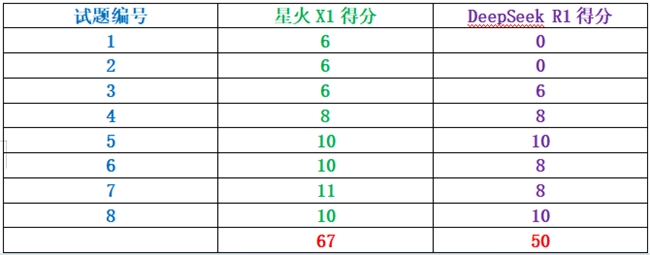
从两大模型本次考试的最终得分来看,星火X1的数学能力不但能全面对标DeepSeek R1,而且实现了超越。
DeepSeek R1最失分的地方是在试题一和试题二,由于图片文字识别错误导致答案错误,这也充分说明,在OCR识别方面,DeepSeek R1和星火X1相比还有一定距离,后期需要改进。
其它方面,两款大模型差别不大,解题前,都会给出逻辑缜密的思考过程,让用户不但知道应该怎么做,还知道为什么要这么做,以后遇到此类问题时应该怎样思考,这一点非常重要,因为它在“喂”的同时,也起到了教书育人的作用,是学生、家长24小时可随时请教的良师益友。
“人工智能的存在不是为锦上添花,而是要解决社会刚需。”此前谈到人工智能,科大讯飞董事长刘庆峰曾表示。本着这一理念,科大讯飞自推出星火大模型后,就将其广泛落地于旗下各业务,比如教育、医疗、智慧汽车、智慧办公、智慧城市等,并针对C端用户,推出AI学习机、智能办公本、翻译机、录音笔,智能耳机等产品。
责任编辑:kj005