дёӯеҚҺзҪ‘家з”ө
и®ҫдёәд№ҰзӯҫCtrl+Dе°Ҷжң¬йЎөйқўдҝқеӯҳдёәд№ҰзӯҫпјҢе…ЁйқўдәҶи§ЈжңҖж–°иө„и®ҜпјҢж–№дҫҝеҝ«жҚ·гҖӮ
1991е№ҙпјҢжҜ”е°”·жҒ©й—ЁпјҲBill InmonпјүеҮәзүҲдәҶд»–зҡ„第дёҖжң¬е…ідәҺж•°жҚ®д»“еә“зҡ„д№ҰгҖҠBuilding the Data WarehouseгҖӢпјҢж Үеҝ—зқҖж•°жҚ®д»“еә“жҰӮеҝөзҡ„зЎ®з«ӢгҖӮ
жҲ‘们жүҖеёёиҜҙзҡ„дјҒдёҡж•°жҚ®д»“еә“Enterprise Data Warehouse (EDW) пјҢе°ұжҳҜдёҖдёӘз”ЁдәҺиҒҡеҗҲдёҚеҗҢжқҘжәҗзҡ„ж•°жҚ®пјҲжҜ”еҰӮдәӢеҠЎзі»з»ҹгҖҒе…ізі»ж•°жҚ®еә“е’Ңж“ҚдҪңж•°жҚ®еә“пјүпјҢ然еҗҺж–№дҫҝиҝӣиЎҢж•°жҚ®и®ҝй—®гҖҒеҲҶжһҗе’ҢжҠҘе‘Ҡзҡ„зі»з»ҹпјҲдҫӢеҰӮй”Җе”®дәӨжҳ“ж•°жҚ®гҖҒ移еҠЁеә”з”Ёж•°жҚ®е’ҢCRMж•°жҚ®пјүпјҢеҸӘиҰҒж•°жҚ®жұҮйӣҶеҲ°ж•°д»“дёӯпјҢж•ҙдёӘдјҒдёҡйғҪи®ҝй—®е’ҢдҪҝз”ЁпјҢд»ҺиҖҢж–№дҫҝеӨ§е®¶жқҘе…Ёйқўзҡ„дәҶи§ЈдёҡеҠЎгҖӮжҲ‘们зҡ„ж•°жҚ®е·ҘзЁӢеёҲе’ҢдёҡеҠЎеҲҶжһҗеёҲеҸҜд»Ҙе°ҶиҝҷдәӣдёҚеҗҢжқҘжәҗзҡ„зӣёе…іж•°жҚ®еә”з”ЁдәҺе•ҶдёҡжҷәиғҪпјҲBIпјүе’Ңдәәе·ҘжҷәиғҪпјҲAIпјүзӯүж–№йқўпјҢд»ҘдҫҝеёҰжқҘжӣҙеҘҪзҡ„йў„жөӢпјҢ并жңҖз»ҲдёәжҲ‘们дҪңеҮәжӣҙеҘҪзҡ„дёҡеҠЎеҶізӯ–гҖӮ
дјҒдёҡдёәд»Җд№ҲйңҖиҰҒе®һж—¶ж•°жҚ®д»“еә“
дј з»ҹж„Ҹд№үдёҠзҡ„ж•°жҚ®д»“еә“дё»иҰҒеӨ„зҗҶT+1ж•°жҚ®пјҢеҚід»ҠеӨ©дә§з”ҹзҡ„ж•°жҚ®еҲҶжһҗз»“жһңжҳҺеӨ©жүҚиғҪзңӢеҲ°пјҢT+1зҡ„жҰӮеҝөжқҘжәҗдәҺиӮЎзҘЁдәӨжҳ“пјҢжҳҜдёҖз§ҚиӮЎзҘЁдәӨжҳ“еҲ¶еәҰпјҢеҚіеҪ“ж—Ҙд№°иҝӣзҡ„иӮЎзҘЁиҰҒеҲ°дёӢдёҖдёӘдәӨжҳ“ж—ҘжүҚиғҪеҚ–еҮәгҖӮ
йҡҸзқҖдә’иҒ”зҪ‘д»ҘеҸҠеҫҲеӨҡиЎҢдёҡзәҝдёҠдёҡеҠЎзҡ„еҝ«йҖҹеҸ‘еұ•пјҢи®©ж•°жҚ®дҪ“йҮҸд»ҘеүҚжүҖжңӘжңүзҡ„йҖҹеәҰеўһй•ҝпјҢж•°жҚ®ж—¶ж•ҲжҖ§еңЁдјҒдёҡиҝҗиҗҘдёӯзҡ„йҮҚиҰҒжҖ§ж—ҘзӣҠеҮёзҺ°пјҢдјҒдёҡеҜ№жө·йҮҸж•°жҚ®зҡ„еӨ„зҗҶжңүдәҶжӣҙй«ҳиҰҒжұӮпјҢеҰӮйқһз»“жһ„еҢ–ж•°жҚ®еӨ„зҗҶгҖҒеҝ«йҖҹжү№еӨ„зҗҶгҖҒе®һж—¶ж•°жҚ®еӨ„зҗҶгҖҒе…ЁйҮҸж•°жҚ®жҢ–жҺҳзӯүгҖӮз”ұдәҺдј з»ҹж•°жҚ®д»“еә“дҫ§йҮҚз»“жһ„еҢ–ж•°жҚ®пјҢе»әжЁЎи·Ҝеҫ„иҫғй•ҝпјҢйқўеҜ№еӨ§и§„жЁЎж•°жҚ®еӨ„зҗҶиғҪеҠӣжңүйҷҗпјҢдјҒдёҡжҖҘйңҖжҸҗеҚҮеӨ§ж•°жҚ®еӨ„зҗҶж—¶ж•ҲпјҢд»Ҙжӣҙз»ҸжөҺзҡ„ж–№ејҸеҸ‘жҺҳж•°жҚ®д»·еҖјгҖӮ
ж•°жҚ®зҡ„е®һж—¶еӨ„зҗҶиғҪеҠӣд№ҹжҲҗдёәдјҒдёҡжҸҗеҚҮз«һдәүеҠӣзҡ„дёҖеӨ§еӣ зҙ гҖӮ
ж•°жҚ®еӨ„зҗҶжөҒзЁӢ
еңЁдәҶи§Јж•°д»“еҰӮдҪ•е®һж—¶еӨ„зҗҶд№ӢеүҚпјҢжҲ‘们е…ҲжқҘдәҶи§Јж•°жҚ®зҡ„еҲҶеұӮгҖӮжҜҸдёӘдјҒдёҡж №жҚ®иҮӘе·ұзҡ„дёҡеҠЎйңҖжұӮеҸҜд»ҘеҲҶжҲҗдёҚеҗҢзҡ„еұӮж¬ЎпјҢдҪҶжҳҜжңҖеҹәзЎҖзҡ„еҲҶеұӮжҖқжғіпјҢзҗҶи®әдёҠж•°жҚ®еҲҶдёәдёүдёӘеұӮпјҡиҙҙжәҗеұӮпјҲODS)гҖҒж•°жҚ®д»“еә“еұӮпјҲDWпјүгҖҒж•°жҚ®жңҚеҠЎеұӮ(APP/DWA)гҖӮеҹәдәҺиҝҷдёӘеҹәзЎҖеҲҶеұӮд№ӢдёҠж»Ўи¶ідёҚеҗҢзҡ„дёҡеҠЎйңҖжұӮгҖӮ
ODSпјҡOperation Data StoreпјҢд№ҹз§°дёәиҙҙжәҗеұӮгҖӮж•°жҚ®д»“еә“жәҗеӨҙзі»з»ҹзҡ„ж•°жҚ®иЎЁйҖҡеёёдјҡеҺҹе°ҒдёҚеҠЁзҡ„еӯҳеӮЁдёҖд»ҪпјҢиҝҷз§°дёәODSеұӮпјҢжҳҜеҗҺз»ӯж•°жҚ®д»“еә“еҠ е·Ҙж•°жҚ®зҡ„жқҘжәҗгҖӮ
DWж•°жҚ®еҲҶеұӮпјҢз”ұдёӢеҲ°дёҠдёҖиҲ¬еҲҶдёәDWDпјҢDWBпјҢDWSгҖӮ
DWDпјҡData Warehouse Details з»ҶиҠӮж•°жҚ®еұӮпјҢжҳҜдёҡеҠЎеұӮдёҺж•°жҚ®д»“еә“зҡ„йҡ”зҰ»еұӮгҖӮдё»иҰҒеҜ№ODSж•°жҚ®еұӮеҒҡдёҖдәӣж•°жҚ®жё…жҙ—(еҺ»йҷӨз©әеҖјгҖҒи„Ҹж•°жҚ®гҖҒи¶…иҝҮжһҒйҷҗиҢғ)е’Ң规иҢғеҢ–зҡ„ж“ҚдҪңгҖӮ
DWBпјҡData Warehouse Base ж•°жҚ®еҹәзЎҖеұӮпјҢеӯҳеӮЁзҡ„жҳҜе®ўи§Ӯж•°жҚ®пјҢдёҖиҲ¬з”ЁдҪңдёӯй—ҙеұӮпјҢеҸҜд»Ҙи®ӨдёәжҳҜеӨ§йҮҸжҢҮж Үзҡ„ж•°жҚ®еұӮгҖӮ
DWSпјҡData Warehouse Service ж•°жҚ®жңҚеҠЎеұӮпјҢеҹәдәҺDWBдёҠзҡ„еҹәзЎҖж•°жҚ®пјҢдё»иҰҒжҳҜеҜ№з”ЁжҲ·иЎҢдёәиҝӣиЎҢиҪ»еәҰиҒҡеҗҲпјҢж•ҙеҗҲжұҮжҖ»жҲҗеҲҶжһҗжҹҗдёҖдёӘдё»йўҳеҹҹзҡ„жңҚеҠЎж•°жҚ®еұӮпјҢдёҖиҲ¬жҳҜе®ҪиЎЁгҖӮз”ЁдәҺжҸҗдҫӣеҗҺз»ӯзҡ„дёҡеҠЎжҹҘиҜўпјҢOLAPеҲҶжһҗпјҢж•°жҚ®еҲҶеҸ‘зӯүгҖӮ
ж•°жҚ®жңҚеҠЎеұӮ/еә”з”ЁеұӮ(APP/DWA)пјҡиҜҘеұӮдё»иҰҒжҳҜжҸҗдҫӣж•°жҚ®дә§е“Ғе’Ңж•°жҚ®еҲҶжһҗдҪҝз”Ёзҡ„ж•°жҚ®пјҢжҲ‘们йҖҡиҝҮиҜҙзҡ„жҠҘиЎЁж•°жҚ®пјҢжҲ–иҖ…иҜҙйӮЈз§ҚеӨ§е®ҪиЎЁпјҢдёҖиҲ¬е°ұж”ҫеңЁиҝҷйҮҢгҖӮ
е®һж—¶ж•°д»“зҡ„еёёи§Ғж–№жЎҲ
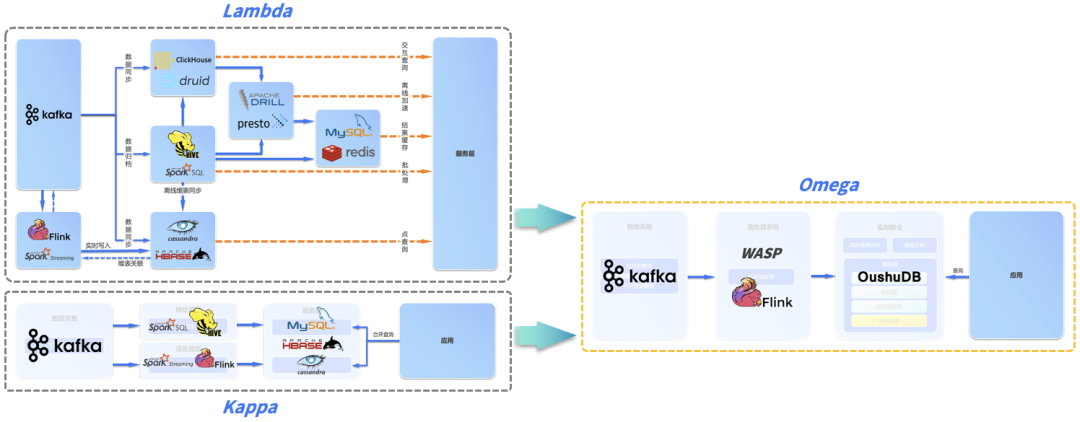
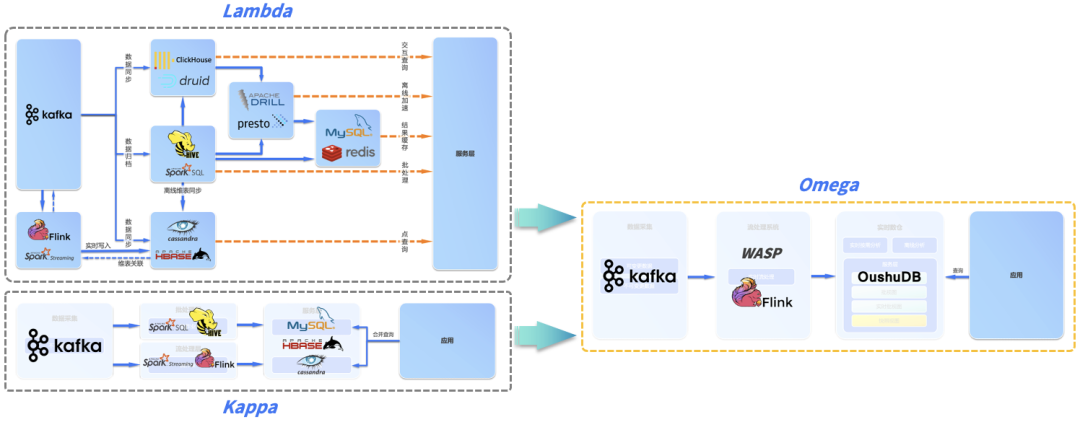
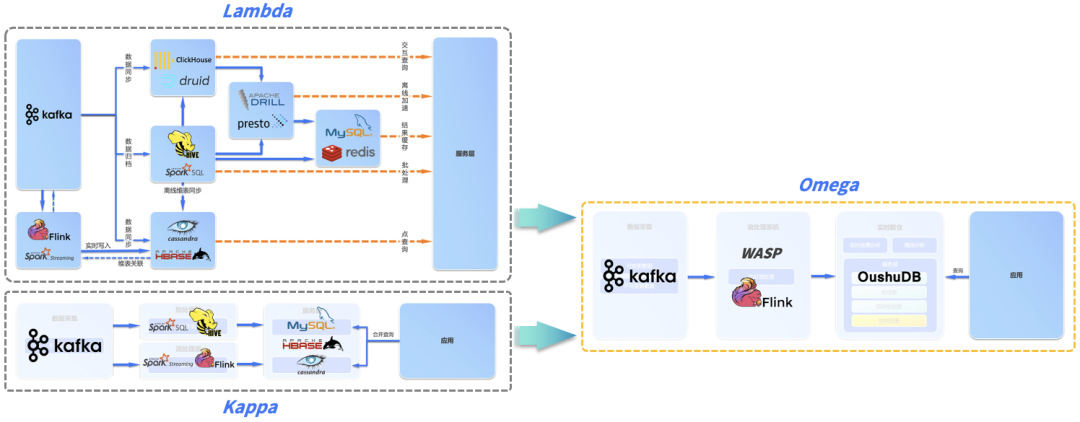
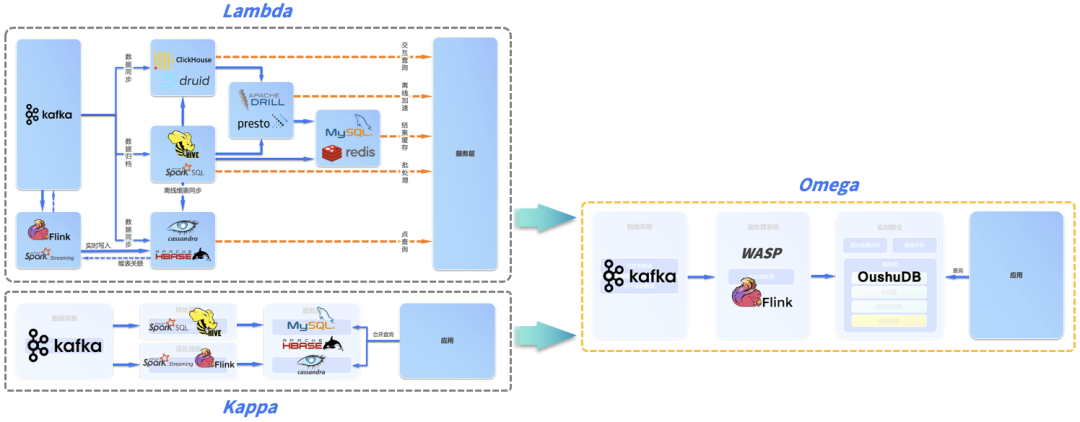
еҪ“еүҚпјҢж•°жҚ®д»“еә“иў«еҲҶдёәзҰ»зәҝж•°д»“е’Ңе®һж—¶ж•°д»“пјҢзҰ»зәҝж•°д»“дёҖиҲ¬жҳҜдј з»ҹзҡ„T+1еһӢж•°жҚ®ETLж–№жЎҲпјҢиҖҢе®һж—¶ж•°д»“дёҖиҲ¬жҳҜеҲҶй’ҹзә§з”ҡиҮіжҳҜз§’зә§ETLж–№жЎҲгҖӮ并且пјҢзҰ»зәҝж•°д»“е’Ңе®һж—¶ж•°д»“зҡ„еә•еұӮжһ¶жһ„д№ҹдёҚдёҖж ·пјҢзҰ»зәҝж•°д»“дёҖиҲ¬йҮҮз”Ёдј з»ҹеӨ§ж•°жҚ®жһ¶жһ„жЁЎејҸжҗӯе»әпјҢиҖҢе®һж—¶ж•°д»“еҲҷйҮҮз”ЁLambdaгҖҒKappaзӯүжһ¶жһ„жҗӯе»әгҖӮ
LAMBDA & KAPPA е®һж—¶жһ¶жһ„
зӣ®еүҚпјҢе®һж—¶еӨ„зҗҶжңүдёӨз§Қе…ёеһӢзҡ„жһ¶жһ„пјҡLambda е’Ң Kappa жһ¶жһ„гҖӮеҮәдәҺеҺҶеҸІеҺҹеӣ пјҢиҝҷдёӨз§Қжһ¶жһ„зҡ„дә§з”ҹе’ҢеҸ‘еұ•йғҪе…·жңүдёҖе®ҡеұҖйҷҗжҖ§гҖӮ
Lambdaжһ¶жһ„пјҡеңЁзҰ»зәҝеӨ§ж•°жҚ®жһ¶жһ„зҡ„еҹәзЎҖдёҠеўһеҠ ж–°й“ҫи·Ҝз”ЁдәҺе®һж—¶ж•°жҚ®еӨ„зҗҶпјҢйңҖиҰҒз»ҙжҠӨзҰ»зәҝеӨ„зҗҶе’Ңе®һж—¶еӨ„зҗҶдёӨеҘ—д»Јз Ғпјӣ
Lambda жһ¶жһ„йҖҡиҝҮжҠҠж•°жҚ®еҲҶи§ЈдёәжңҚеҠЎеұӮпјҲServing LayerпјүгҖҒйҖҹеәҰеұӮпјҲSpeed LayerпјҢдәҰеҚіжөҒеӨ„зҗҶеұӮпјүгҖҒжү№еӨ„зҗҶеұӮпјҲBatch LayerпјүдёүеұӮжқҘи§ЈеҶідёҚеҗҢж•°жҚ®йӣҶзҡ„ж•°жҚ®йңҖжұӮгҖӮеңЁжү№еӨ„зҗҶеұӮдё»иҰҒеҜ№зҰ»зәҝж•°жҚ®иҝӣиЎҢеӨ„зҗҶпјҢе°ҶжҺҘе…Ҙзҡ„ж•°жҚ®иҝӣиЎҢйў„еӨ„зҗҶе’ҢеӯҳеӮЁпјҢжҹҘиҜўзӣҙжҺҘеңЁйў„еӨ„зҗҶз»“жһңдёҠиҝӣиЎҢпјҢдёҚйңҖеҶҚиҝӣиЎҢе®Ңж•ҙзҡ„и®Ўз®—пјҢжңҖеҗҺд»Ҙжү№и§Ҷеӣҫзҡ„еҪўејҸжҸҗдҫӣз»ҷдёҡеҠЎеә”з”ЁгҖӮ
еңЁе®һйҷ…з”ҹдә§зҺҜеўғдёӯзҡ„йғЁзҪІйҖҡеёёеҸҜд»ҘеҸӮи§ҒдёӢеӣҫпјҢдёҖиҲ¬иҰҒйҖҡиҝҮдёҖзі»еҲ—дёҚеҗҢзҡ„еӯҳеӮЁе’Ңи®Ўз®—еј•ж“Һ (HBaseгҖҒDruidгҖҒHiveгҖҒPrestoгҖҒRedis зӯү) еӨҚжқӮеҚҸеҗҢжүҚиғҪж»Ўи¶ідёҡеҠЎзҡ„е®һж—¶йңҖжұӮпјҢжӯӨеӨ–еӨҡдёӘеӯҳеӮЁд№Ӣй—ҙйңҖиҰҒйҖҡиҝҮж•°жҚ®еҗҢжӯҘд»»еҠЎдҝқжҢҒеӨ§иҮҙзҡ„еҗҢжӯҘгҖӮLambda жһ¶жһ„еңЁе®һйҷ…иҗҪең°иҝҮзЁӢдёӯжһҒе…¶еӨҚжқӮпјҢдҪҝж•ҙдёӘдёҡеҠЎзҡ„ејҖеҸ‘иҖ—иҙ№дәҶеӨ§йҮҸзҡ„ж—¶й—ҙгҖӮ
зјәзӮ№пјҡ
(1) з”ұеӨҡдёӘеј•ж“Һе’Ңзі»з»ҹз»„еҗҲиҖҢжҲҗпјҢжү№еӨ„зҗҶ (Batch)гҖҒжөҒеӨ„зҗҶ (Streaming) д»ҘеҸҠеҗҲ并жҹҘиҜў (Merged Query) зҡ„е®һзҺ°йңҖиҰҒдҪҝз”ЁдёҚеҗҢзҡ„ејҖеҸ‘иҜӯиЁҖпјҢйҖ жҲҗејҖеҸ‘гҖҒз»ҙжҠӨе’ҢеӯҰд№ жҲҗжң¬иҫғй«ҳпјӣ(2) ж•°жҚ®еңЁдёҚеҗҢзҡ„и§Ҷеӣҫ (View) дёӯеӯҳеӮЁеӨҡд»ҪпјҢжөӘиҙ№еӯҳеӮЁз©әй—ҙпјҢж•°жҚ®дёҖиҮҙжҖ§зҡ„й—®йўҳйҡҫд»Ҙи§ЈеҶігҖӮ
Kappaжһ¶жһ„пјҡеёҢжңӣеҒҡеҲ°жү№жөҒеҗҲдёҖпјҢзҰ»зәҝеӨ„зҗҶе’Ңе®һж—¶еӨ„зҗҶж•ҙеҗҲжҲҗдёҖеҘ—д»Јз ҒпјҢеҮҸе°Ҹиҝҗз»ҙжҲҗжң¬гҖӮKappa жһ¶жһ„еңЁ Lambda жһ¶жһ„зҡ„еҹәзЎҖдёҠ移йҷӨдәҶжү№еӨ„зҗҶеұӮпјҢеҲ©з”ЁжөҒи®Ўз®—зҡ„еҲҶеёғејҸзү№еҫҒпјҢеҠ еӨ§жөҒж•°жҚ®зҡ„ж—¶й—ҙзӘ—еҸЈпјҢз»ҹдёҖжү№еӨ„зҗҶе’ҢжөҒеӨ„зҗҶпјҢеӨ„зҗҶеҗҺзҡ„ж•°жҚ®еҸҜд»ҘзӣҙжҺҘз»ҷеҲ°дёҡеҠЎеұӮдҪҝз”ЁгҖӮеӣ дёәеңЁ Kappa жһ¶жһ„дёӢпјҢдҪңдёҡеӨ„зҗҶзҡ„жҳҜжүҖжңүеҺҶеҸІж•°жҚ®е’ҢеҪ“еүҚж•°жҚ®пјҢе…¶дә§з”ҹзҡ„з»“жһңжҲ‘们称д№Ӣдёәе®һж—¶жү№и§ҶеӣҫпјҲRealtime_Batch_ViewпјүгҖӮ
Kappa жһ¶жһ„зҡ„жөҒеӨ„зҗҶзі»з»ҹйҖҡеёёдҪҝз”Ё Spark Streaming жҲ–иҖ… Flink зӯүе®һзҺ°пјҢжңҚеҠЎеұӮйҖҡеёёдҪҝз”ЁMySQL жҲ– HBase зӯүе®һзҺ°гҖӮ
Kappa жһ¶жһ„йғЁзҪІеӣҫ
зјәзӮ№пјҡ(1) дҫқиө– Kafka зӯүж¶ҲжҒҜйҳҹеҲ—жқҘдҝқеӯҳжүҖжңүеҺҶеҸІпјҢиҖҢKafka йҡҫд»Ҙе®һзҺ°ж•°жҚ®зҡ„жӣҙж–°е’Ңзә й”ҷпјҢеҸ‘з”ҹж•…йҡңжҲ–иҖ…еҚҮзә§ж—¶йңҖиҰҒйҮҚеҒҡжүҖжңүеҺҶеҸІпјҢе‘Ёжңҹиҫғй•ҝпјӣ(2) Kappa дҫқ然жҳҜй’ҲеҜ№дёҚеҸҜеҸҳжӣҙж•°жҚ®пјҢж— жі•е®һж—¶жұҮйӣҶеӨҡдёӘеҸҜеҸҳж•°жҚ®жәҗеҪўжҲҗзҡ„ж•°жҚ®йӣҶеҝ«з…§пјҢдёҚйҖӮеҗҲеҚіеёӯжҹҘиҜўгҖӮ
еӣ дёәдёҠиҝ°зҡ„зјәзӮ№пјҢKappaжһ¶жһ„еңЁзҺ°е®һдёӯеҫҲе°‘иў«еә”з”ЁгҖӮ
ж№–д»“дёҖдҪ“иғҪеҗҰи§ЈеҶіе®һж—¶й—®йўҳпјҹ
ж—¶дёӢзғӯй—Ёзҡ„ж№–д»“дёҖдҪ“иғҪеҗҰи§ЈеҶіе®һж—¶й—®йўҳе‘ўпјҹж№–д»“дёҖдҪ“жңүдҪ•ж ҮеҮҶпјҹGartner и®Өдёәж№–д»“дёҖдҪ“жҳҜе°Ҷж•°жҚ®ж№–зҡ„зҒөжҙ»жҖ§е’Ңж•°д»“зҡ„жҳ“з”ЁжҖ§гҖҒ规иҢғжҖ§гҖҒй«ҳжҖ§иғҪз»“еҗҲиө·жқҘзҡ„иһҚеҗҲжһ¶жһ„пјҢж— ж•°жҚ®еӯӨеІӣгҖӮ
дҪңдёәж•°жҚ®ж№–е’Ңж•°жҚ®д»“еә“зҡ„е®ҢзҫҺз»“еҗҲпјҢж–°дёҖд»Јзҡ„ж№–д»“дёҖдҪ“жһ¶жһ„йҮҚзӮ№е…іжіЁе’Ңи§ЈеҶідәҶиҝ‘е№ҙжқҘж•°еӯ—еҢ–иҪ¬еһӢеёҰжқҘзҡ„дёҡеҠЎйңҖжұӮе’ҢжҠҖжңҜйҡҫзӮ№пјҢе…·дҪ“еҢ…жӢ¬еҰӮдёӢд»ҘдёӢж–№йқўпјҡ
1.е®һж—¶жҖ§жҲҗдёәдәҶжҸҗеҚҮдјҒдёҡз«һдәүеҠӣзҡ„ж ёеҝғжүӢж®өгҖӮзӣ®еүҚзҡ„ж№–гҖҒд»“гҖҒжҲ–иҖ…ж№–д»“еҲҶдҪ“йғҪжҳҜеҹәдәҺ T+1 и®ҫи®Ўзҡ„пјҢйқўеҜ№ T+0 зҡ„е®һж—¶жҢүйңҖеҲҶжһҗпјҢз”ЁжҲ·зҡ„йңҖжұӮж— жі•ж»Ўи¶ігҖӮ
2.жүҖжңүз”ЁжҲ·пјҲBI з”ЁжҲ·гҖҒж•°жҚ®з§‘еӯҰ家зӯүпјүеҸҜд»Ҙе…ұдә«еҗҢдёҖд»Ҫж•°жҚ®пјҢйҒҝе…Қж•°жҚ®еӯӨеІӣгҖӮ
3.и¶…й«ҳ并еҸ‘иғҪеҠӣпјҢж”ҜжҢҒж•°еҚҒдёҮз”ЁжҲ·дҪҝз”ЁеӨҚжқӮеҲҶжһҗжҹҘиҜўе№¶еҸ‘и®ҝй—®еҗҢдёҖд»Ҫж•°жҚ®гҖӮ
4.дј з»ҹ Hadoop еңЁдәӢеҠЎж”ҜжҢҒзӯүж–№йқўзҡ„дёҚи¶іиў«еӨ§е®¶иҜҹз—…пјҢеңЁй«ҳйҖҹеҸ‘еұ•д№ӢеҗҺжңӘиғҪ延з»ӯзғӯеәҰпјҢжҢҒз»ӯеј•йўҶж•°жҚ®з®ЎзҗҶпјҢеӣ жӯӨдәӢеҠЎж”ҜжҢҒеңЁж№–д»“дёҖдҪ“жһ¶жһ„дёӯеә”еҫ—еҲ°ж”№е–„е’ҢжҸҗеҚҮгҖӮ
5.дә‘еҺҹз”ҹж•°жҚ®еә“е·Із»ҸйҖҗжёҗжҲҗзҶҹпјҢеҹәдәҺеӯҳз®—еҲҶзҰ»жҠҖжңҜпјҢеҸҜд»Ҙз»ҷз”ЁжҲ·еёҰжқҘеӨҡз§Қд»·еҖјпјҡйҷҚдҪҺжҠҖжңҜй—Ёж§ӣгҖҒеҮҸе°‘з»ҙжҠӨжҲҗжң¬гҖҒжҸҗеҚҮз”ЁжҲ·дҪ“йӘҢгҖҒиҠӮзңҒиө„жәҗиҙ№з”ЁпјҢе·ІжҲҗдёәдәҶж№–д»“дёҖдҪ“иҗҪең°зҡ„йҮҚиҰҒжі•й—ЁгҖӮ
6.дёәйҮҠж”ҫж•°жҚ®д»·еҖјжҸҗеҚҮдјҒдёҡжҷәиғҪеҢ–ж°ҙе№іпјҢж•°жҚ®з§‘еӯҰ家зӯүз”ЁжҲ·и§’иүІеҝ…йЎ»йҖҡиҝҮеӨҡз§Қзұ»еһӢж•°жҚ®иҝӣиЎҢе…Ёеҹҹж•°жҚ®жҢ–жҺҳпјҢеҢ…жӢ¬дҪҶдёҚйҷҗдәҺеҺҶеҸІзҡ„гҖҒе®һж—¶зҡ„гҖҒеңЁзәҝзҡ„гҖҒзҰ»зәҝзҡ„гҖҒеҶ…йғЁзҡ„гҖҒеӨ–йғЁзҡ„гҖҒз»“жһ„еҢ–зҡ„гҖҒйқһз»“жһ„еҢ–ж•°жҚ®гҖӮ
дә‘еҺҹз”ҹж•°жҚ®д»“еә“ + Omegaе®һж—¶жһ¶жһ„ е®һзҺ°е®һж—¶ж№–д»“
дә‘еҺҹз”ҹж•°жҚ®еә“е®һзҺ°е®Ңе…Ёзҡ„еӯҳз®—еҲҶзҰ»
дә‘еҺҹз”ҹж•°жҚ®еә“еҰӮ OushuDB е’Ң Snowflake зӘҒз ҙдәҶдј з»ҹ MPP е’Ң Hadoop зҡ„еұҖйҷҗжҖ§пјҢе®һзҺ°дәҶеӯҳз®—е®Ңе…ЁеҲҶзҰ»пјҢи®Ўз®—е’ҢеӯҳеӮЁеҸҜйғЁзҪІеңЁдёҚеҗҢзү©зҗҶйӣҶзҫӨпјҢ并йҖҡиҝҮиҷҡжӢҹи®Ўз®—йӣҶзҫӨжҠҖжңҜе®һзҺ°дәҶй«ҳ并еҸ‘пјҢеҗҢж—¶дҝқйҡңдәӢеҠЎж”ҜжҢҒпјҢжҲҗдёәж№–д»“дёҖдҪ“е®һзҺ°зҡ„е…ій”®жҠҖжңҜгҖӮд»Ҙ OushuDB дёәдҫӢпјҢе®һзҺ°дәҶеӯҳз®—еҲҶзҰ»зҡ„дә‘еҺҹз”ҹжһ¶жһ„пјҢ并йҖҡиҝҮиҷҡжӢҹи®Ўз®—йӣҶзҫӨжҠҖжңҜеңЁж•°еҚҒдёҮиҠӮзӮ№зҡ„и¶…еӨ§и§„жЁЎйӣҶзҫӨдёҠе®һзҺ°дәҶй«ҳ并еҸ‘пјҢдҝқйҡңдәӢеҠЎж”ҜжҢҒпјҢжҸҗдҫӣе®һж—¶иғҪеҠӣпјҢдёҖд»Ҫж•°жҚ®еҶҚж— ж•°жҚ®еӯӨеІӣгҖӮ
еҹәдәҺOmegaе®һж—¶жЎҶжһ¶зҡ„ж№–д»“ж–№жЎҲ
жҲ‘们еүҚйқўжҸҗеҲ°пјҢ既然 Kappa жһ¶жһ„е®һйҷ…иҗҪең°еӣ°йҡҫпјҢLambda жһ¶жһ„еҸҲеҫҲйҡҫдҝқйҡңж•°жҚ®зҡ„дёҖиҮҙжҖ§пјҢдёӨдёӘжһ¶жһ„еҸҲйғҪеҫҲйҡҫеӨ„зҗҶеҸҜеҸҳжӣҙж•°жҚ®пјҲеҰӮе…ізі»ж•°жҚ®еә“дёӯдёҚеҒңеҸҳеҢ–зҡ„е®һж—¶ж•°жҚ®пјүпјҢйӮЈд№ҲиҮӘ然йңҖиҰҒдёҖз§Қж–°зҡ„жһ¶жһ„ж»Ўи¶ідјҒдёҡе®һж—¶еҲҶжһҗзҡ„е…ЁйғЁйңҖжұӮпјҢиҝҷе°ұжҳҜ Omega е…Ёе®һж—¶жһ¶жһ„пјҢOmega жһ¶жһ„з”ұеҒ¶ж•°з§‘жҠҖж №жҚ®е…¶еңЁеҗ„иЎҢдёҡзҡ„е®һи·өжҸҗеҮәпјҢеҗҢж—¶ж»Ўи¶іе®һж—¶жөҒеӨ„зҗҶгҖҒе®һж—¶жҢүйңҖеҲҶжһҗе’ҢзҰ»зәҝеҲҶжһҗгҖӮ
Omega жһ¶жһ„з”ұжөҒж•°жҚ®еӨ„зҗҶзі»з»ҹе’Ңе®һж—¶ж•°д»“жһ„жҲҗгҖӮзӣёжҜ” Lambda е’Ң KappaпјҢOmega жһ¶жһ„ж–°еј•е…ҘдәҶе®һж—¶ж•°д»“е’Ңеҝ«з…§и§Ҷеӣҫ (Snapshot View) зҡ„жҰӮеҝөпјҢеҝ«з…§и§ҶеӣҫжҳҜеҪ’йӣҶдәҶеҸҜеҸҳжӣҙж•°жҚ®жәҗе’ҢдёҚеҸҜеҸҳжӣҙж•°жҚ®жәҗеҗҺеҪўжҲҗзҡ„ T+0 е®һж—¶еҝ«з…§пјҢеҸҜд»ҘзҗҶи§ЈдёәжүҖжңүж•°жҚ®жәҗеңЁе®һж—¶ж•°д»“дёӯзҡ„й•ңеғҸе’ҢеҺҶеҸІпјҢйҡҸзқҖжәҗеә“зҡ„еҸҳеҢ–е®һж—¶еҸҳеҢ–гҖӮ
еӣ жӯӨпјҢе®һж—¶жҹҘиҜўеҸҜд»ҘйҖҡиҝҮеӯҳеӮЁдәҺе®һж—¶ж•°д»“зҡ„еҝ«з…§и§Ҷеӣҫеҫ—д»Ҙе®һзҺ°гҖӮе®һж—¶еҝ«з…§жҸҗдҫӣзҡ„еңәжҷҜеҸҜд»ҘеҲҶдёәдёӨеӨ§зұ»пјҡдёҖзұ»жҳҜеӨҡдёӘжәҗеә“жұҮйӣҶеҗҺзҡ„и·Ёеә“жҹҘиҜўпјҢжҜ”еҰӮдёҖдёӘдҝқйҷ©з”ЁжҲ·зҡ„жқғзӣҠи§ҶеӣҫпјӣеҸҰдёҖзұ»жҳҜд»»ж„Ҹж—¶й—ҙзІ’еәҰзҡ„еҲҶжһҗжҹҘиҜўпјҢжҜ”еҰӮжңҖиҝ‘ 5 еҲҶй’ҹзҡ„дәӨжҳ“йҮҸгҖҒжңҖиҝ‘ 10 еҲҶй’ҹзҡ„дҝЎз”ЁеҚЎејҖеҚЎйҮҸзӯүзӯүгҖӮ
еҸҰеӨ–пјҢд»»ж„Ҹж—¶й—ҙзӮ№зҡ„еҺҶеҸІж•°жҚ®йғҪеҸҜд»ҘйҖҡиҝҮ T+0 еҝ«з…§еҫ—еҲ°пјҲдёәдәҶиҠӮзңҒеӯҳеӮЁпјҢT+0 еҝ«з…§еҸҜд»ҘжӢүй“ҫеҪўејҸеӯҳеӮЁеңЁе®һж—¶ж•°д»“ ODS дёӯпјҢжүҖд»Ҙеҝ«з…§и§ҶеӣҫеҸҜд»ҘзҗҶи§Јдёәе®һж—¶жӢүй“ҫпјүпјҢиҝҷж ·зҰ»зәҝжҹҘиҜўеҸҜд»ҘеңЁе®һж—¶ж•°д»“дёӯе®ҢжҲҗпјҢзҰ»зәҝжҹҘиҜўз»“жһңеҸҜд»ҘеҢ…еҗ«жңҖж–°зҡ„е®һж—¶ж•°жҚ®пјҢе®Ңе…ЁдёҚеҶҚйңҖиҰҒйҖҡиҝҮдј з»ҹMPP+Hadoopж№–д»“еҲҶдҪ“з»„еҗҲжқҘеӨ„зҗҶзҰ»зәҝи·‘жү№еҸҠеҲҶжһҗжҹҘиҜўгҖӮ
Omega жһ¶жһ„йҖ»иҫ‘еӣҫ
жөҒеӨ„зҗҶзі»з»ҹж—ўеҸҜд»Ҙе®һзҺ°е®һж—¶иҝһз»ӯзҡ„жөҒеӨ„зҗҶпјҢд№ҹеҸҜд»Ҙе®һзҺ° Kappa жһ¶жһ„дёӯзҡ„жү№жөҒдёҖдҪ“пјҢдҪҶдёҺKappa жһ¶жһ„дёҚеҗҢзҡ„жҳҜпјҢOushuDB е®һж—¶ж•°д»“еӯҳеӮЁжқҘиҮӘ Kafka зҡ„е…ЁйғЁеҺҶеҸІж•°жҚ®пјҲиҜҰи§ҒдёӢеӣҫпјүпјҢиҖҢеңЁ Kappa жһ¶жһ„дёӯжәҗз«ҜйҮҮйӣҶеҗҺйҖҡеёёеӯҳеӮЁеңЁ Kafka дёӯгҖӮ
Omega жһ¶жһ„йғЁзҪІеӣҫ
еӣ жӯӨпјҢеҪ“йңҖиҰҒжөҒеӨ„зҗҶзүҲжң¬еҸҳжӣҙзҡ„ж—¶еҖҷпјҢжөҒеӨ„зҗҶеј•ж“ҺдёҚеҶҚйңҖиҰҒи®ҝй—® KafkaпјҢиҖҢжҳҜи®ҝй—®е®һж—¶ж•°д»“ OushuDB иҺ·еҫ—жүҖжңүеҺҶеҸІж•°жҚ®пјҢ规йҒҝдәҶ Kafka йҡҫд»Ҙе®һзҺ°ж•°жҚ®жӣҙж–°е’Ңзә й”ҷзҡ„й—®йўҳпјҢеӨ§е№…жҸҗй«ҳж•ҲзҺҮгҖӮжӯӨеӨ–пјҢж•ҙдёӘжңҚеҠЎеұӮд№ҹеҸҜд»ҘеңЁе®һж—¶ж•°д»“дёӯе®һзҺ°пјҢиҖҢж— йңҖйўқеӨ–еј•е…Ҙ MySQLгҖҒHBase зӯү组件пјҢжһҒеӨ§з®ҖеҢ–дәҶж•°жҚ®жһ¶жһ„пјҢе®һзҺ°дәҶж№–д»“еёӮдёҖдҪ“пјҲж•°жҚ®ж№–гҖҒж•°д»“гҖҒйӣҶеёӮдёҖдҪ“пјүгҖӮе®һзҺ°дәҶе…Ёе®һж—¶ Omega жһ¶жһ„зҡ„ж№–д»“дёҖдҪ“пјҢжҲ‘们д№ҹз§°д№Ӣдёәе®һж—¶ж№–д»“дёҖдҪ“гҖӮ

Omega vs. Lambda vs. Kappa
з»“иҜӯпјҡ
йқўеҜ№еӨҚжқӮеӨҡеҸҳзҡ„ж–°дёҡеҠЎеңәжҷҜпјҢйҡҸзқҖж•°жҚ®жҠҖжңҜдёҚж–ӯжҲҗзҶҹпјҢж–°зҡ„е®һж—¶жҠҖжңҜж ҲдјҡеҮәзҺ°пјҢж•°жҚ®жҠҖжңҜд№ҹдјҡз»ҸеҺҶеҲҶзҰ»дёҺиһҚеҗҲгҖӮзӣ®еүҚпјҢиһҚеҗҲзҡ„и¶ӢеҠҝжҜ”иҫғжҳҺжҳҫпјҢеҰӮе®һж—¶ж№–д»“дёҖдҪ“пјҢе°Ҷе®һж—¶еӨ„зҗҶиғҪеҠӣиһҚе…Ҙж•°жҚ®д»“еә“дёӯгҖӮдёҚи®әдјҒдёҡеҰӮдҪ•йҖүеһӢе®һж—¶ж•°д»“пјҢж•°жҚ®е№іеҸ°жҠҖжңҜж Ҳзҡ„е»әи®ҫдёҖиҲ¬йғҪеә”иҜҘйҒөеҫӘдёүжқЎеҹәжң¬еҺҹеҲҷпјҡ
1.жһ¶жһ„еұӮйқўиҰҒдҝқжҢҒзҒөжҙ»ејҖж”ҫпјҢж”ҜжҢҒеӨҡз§ҚжҠҖжңҜе…је®№жҖ§е№¶еӯҳгҖӮзӣ®еүҚпјҢдјҒдёҡе·Із»ҸйғЁзҪІдәҶеӨҡдёӘзі»з»ҹпјҢжңүиҮӘе·ұзҡ„дёҖеҘ—жһ¶жһ„дҪ“зі»пјҢжҠҖжңҜиһҚеҗҲиҗҪең°ж—¶йңҖиҰҒжңҖеӨ§еҢ–еҲ©з”ЁдјҒдёҡеҺҹжңүITиө„дә§пјҢдҝқжҠӨе®ўжҲ·жҠ•иө„гҖӮ
2.жңүж•ҲеҲ©з”Ёиө„жәҗпјҢйҷҚжң¬еўһж•ҲгҖӮеҺҹжқҘдј з»ҹзҡ„жҠҖжңҜж ҲпјҢжүҖжңүиө„жәҗеҸӮдёҺи®Ўз®—пјҢйҖ жҲҗITиө„жәҗжөӘиҙ№гҖӮжҜ”еҰӮпјҢдә‘еҺҹз”ҹиө„жәҗжұ еҢ–пјҢеҸҜд»Ҙе®һзҺ°иө„жәҗйҡ”зҰ»дёҺеҠЁжҖҒз®ЎзҗҶпјҢдҫҝдәҺжңҖеӨ§еҢ–еҲ©з”Ёиө„жәҗгҖӮ
3.ж»Ўи¶іжӣҙй«ҳзҡ„з”ЁжҲ·дҪ“йӘҢгҖӮд»Һз”ЁжҲ·и§’еәҰжқҘзңӢпјҢеңЁжҠҖжңҜжқЎд»¶е…·еӨҮзҡ„еүҚжҸҗдёӢпјҢжҜ”еҰӮй«ҳжҖ§иғҪгҖҒй«ҳ并еҸ‘гҖҒе®һж—¶жҖ§жӣҙејәпјҢдҫҝе…·еӨҮдәҶжӣҙејәзҡ„дҝЎжҒҜеҠ е·ҘиғҪеҠӣпјҢиғҪеӨҹеңЁеҫҲзҹӯзҡ„ж—¶й—ҙеҶ…ж»Ўи¶із”ЁжҲ·еҗ„з§Қеҗ„ж ·зҡ„ж•°жҚ®жңҚеҠЎйңҖжұӮпјҢжҸҗеҚҮз”ЁжҲ·дҪ“йӘҢгҖӮ
йҡҸзқҖе®һж—¶еҲҶжһҗеңәжҷҜж—ҘзӣҠеўһеӨҡпјҢе®һж—¶ж•°д»“зӯүе…·еӨҮе®һж—¶еӨ„зҗҶиғҪеҠӣзҡ„дә§е“ҒдёҺи§ЈеҶіж–№жЎҲе°Ҷдјҡеҫ—еҲ°жӣҙе№ҝжіӣзҡ„еә”з”ЁгҖӮ
е…ҚиҙЈеЈ°жҳҺпјҡеёӮеңәжңүйЈҺйҷ©пјҢйҖүжӢ©йңҖи°Ёж…ҺпјҒжӯӨж–Үд»…дҫӣеҸӮиҖғпјҢдёҚдҪңд№°еҚ–дҫқжҚ®гҖӮ
иҙЈд»»зј–иҫ‘пјҡkj005
ж–Үз« жҠ•иҜүзғӯзәҝ:156 0057 2229 жҠ•иҜүйӮ®з®ұ:29132 36@qq.com












